SWRC) A Non-morphological Approach for DBpedia URI spotting within Korean Text 논문 요약.
<A
Non-morphological Approach for DBpedia URI spotting within Korean Text.>
Abstract
- - URI Spotting (URI 탐지) 문제는 텍스트에 있는 단어열 중에서 URI로 대표되는 개체를 탐지하는 것.
- - 어느 단어열이 URI에 해당하는 개체인가를 탐지하는 문제, 개체 중의 해소 문제로 두 가지 문제 존재.
- - 개체명 인식 문제와 비슷하나, URI에 매핑되는 개체로 한정.
- - 한국어 텍스트를 대상으로 SVM을 이용하는 개체 경계 인식 방법
- - 의미모호성 문제는 LDA를 활용.
Introduction
- - LOD (linked open
data) 개체를 자동으로 인식할 수
있는 능력은 웹 상의 비정형 데이터를 링크드 데이터와 연결하여 지식베이스를 넓히는 데 중요.
- - DBpedia URI 탐지 과정은 두 단계로 이루어짐
o
개체 경계 인식: text 속에서 DBpedia 개체에 해당하는 단어열 검출
o
개체 중의성 해소: 검출한 단어열이 각각 어떤 DBpedia와 연결되는지.
o
한국어처럼 개체명이 짧은 경우, 단순 문자열 알고리즘은 불리 -> SVM
사용.
o
LDB 토픽 모델로 개체 중의성 해소 문제 해결 시도.
Related
Works
- - DBpedia URI 탐지는 개체명 인식과는 다름. 개체명 인식은 장소, 단체같은 class 부여가 목적, URI는 관련 어휘들을 태그해야함
문제 정의
- - 데이터 집합: Wikipedia Extractor와 한국어 위키피디아 덤프 사용.
- - 개체 정의: 한국어 디비피디아로 한정 짓고, 리다이렉션, 동음이의어와 같은 특수 URI는 제외.
- - 개체 경계 인식의 범위: 데이터 집합 내의 모든 링크의 단어열로 구성된 사전 제작, 이 사전 내 포함된 단어열만을 개체가 가질 수 있는 단어열의 범위로 제한.
개체 경계 인식 실험
- - 한국어는 개체의 대부분의 글자 수가 짧기 때문에 서로 위치상으로 겹치는 개체가 굉장히 많음.
o
간단한 해결책은 청킹을 실행하는 것이나 한국어의 접두사, 접미사와 같은 특징 때문에 좋지는 않음.
o
개체라고 생각되는 경계들의 부분 집합을 만든 뒤 가장 긴 경계를 사용.

- - 개체 판별 알고리즘
o
베이스라인: 후보자들 내의 모든 경계를 개체로 인정함.
o
어절 기반: 후보자들 내 경계 중 단어열의 바로 앞과 뒤 공백, 특수문자가 있는 경계만.
o
접두와 접미 기반: 경계 바로 뒤 문자가 공백 뿐만 아니라 접미사 포함.
o
품사 기반: 최신 한국어 품사 태거로 전체 단어열을 품사 단위로 쪼갬.
o
SVM 기반: SVM의 여러 커널들을 이용하여 정답 집합 일부가지고 학습.
- - 성능 평가와 실험 결과
o
CoNLL-2003 showed
task의 성능 측정 방식, 5-fold cross validation 진행.
o
실험 결과는 SVM-4에서 F-Score가 80.91로 전반적으로 좋아짐.

개체 중의성 해소 실험
- - 개체 경계 인식과정에서 생긴 오류는 모두 개체 중의성 과정으로 전파됨. 이를 통해 성능을 높이기 위해선 경계의 단어열이 해당 문제에서 가지는 의미 파악 중요.

- - 개체 중의성 해소 알고리즘
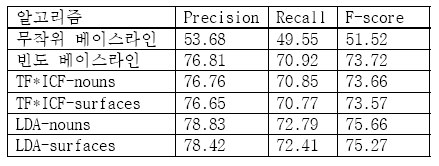
o
무작위 베이스라인: 후보자들중 무작위 선택 | 빈도 베이스라인: 더 많이 링크된 URI 선택
o
TF*ICF: 문서 유사도를 통해 후보자들 중 단어열을 가진 문서와 평균적으로 가장 유사한 URI 선택, Bag of Words를 통해 모든 연속된 명사구를 만드는 방식은 noun, 개체 경계 인식 과정을 통해 만드는 방식은 surface
o
LDF: TF*ICF와 유사하나 한국어 위키피디아 전체에 대해 실행하며, 이 역시 방식에 따라 noun, surface. KL-Divergence 계산 이용.
- - 5-fold cross
validation 이용하요,
LDA 알고리즘이 제일 좋은 performance.

댓글
댓글 쓰기