SWRC) Universal Dependency Annotation for Multilingual Parsing 번역, 정리
Universal Dependency Annotation for Multilingual Parsing
Ryan McDonal et al.
* 잘못된 내용 피드백이나 추가하고 싶은 내용을 피드백 해주시는 것을 절대적으로 환영합니다. *
(다국어 분석을 위한 범용 종속성 주석)
Universal Dependency Annotation 의미에서 나타났듯이, 우리는 다언어에 대해 범용적인 종속성 annotation이 필요하다. 예를 들어, 영어의 어순이 s+v+o에 나타나는 반면에, 한국어의 어순은 s+o+v와 같은 형식으로 나타나게 된다. 이러한 언어마다 annotation이 다를 경우에 cross-lingual transfer (교차언어 변환)과 같은 시도시에 오류가 나타날 수 밖에 없다. 따라서 해당 논문에서는 언어의 Dependency Annotation을 범용적으로 통일하려는 시도가 있었다고 생각한다. 이 부분은 parse tree를 생각해보면 쉽게 이해할 수 있다. 한국어의 parse tree, 영어의 parse tree를 만들 때 있어서 token의 종류에 대해 공통적인 부분을 가질 수 있으나 다른 token의 종류로 인식할 수도 있고, 다른 token의 종류로 분류되어야 함에도 같은 token으로 분류될 수 있다. 이러한 부분을 일관성있게 Dependency Annotation을 진행하였다는 의미다.
해당 분야에 대해 지식이 아직 너무 모자라기에 논문을 이해하는 데 굉장히 힘들었고, 아직 이해하지 못한 부분도 있으나 논문을 한국어로 번역하며 각 문단들을 해석하려고 시도해보았다.
Abstract
We present a new collection of treebanks with homogeneous syntactic dependency annotation for six languages: German, English, Swedish, Spanish, French and Korean. To show the usefulness of such a resource, we present a case study of cross-lingual transfer parsing with more reliable evaluation than has been possible before. This 'universal' treebank is made freely available in order to facilitate research on multilingual dependency parsing.
우리는 총 6가지의 언어를 위한 균일한 구문 의존성 annotation을 가진 treebank의 새로운 collection을 제안한다. (독일어, 영어, 스웨덴어, 스페인어, 불어, 한국어)
* 여기서 treebank란, 파싱된 text corpus를 의미하며, 구문적으로 혹인 문법적으로 annotate된 것을 말한다. 구문 의존성 annotation이란 말 그대로 구문의 위치, 주변 단어들의 뜻 등 parse tree에 따라 의존적으로 annotation이 된 것을 의미한다.




Ryan McDonal et al.
* 잘못된 내용 피드백이나 추가하고 싶은 내용을 피드백 해주시는 것을 절대적으로 환영합니다. *
(다국어 분석을 위한 범용 종속성 주석)
Universal Dependency Annotation 의미에서 나타났듯이, 우리는 다언어에 대해 범용적인 종속성 annotation이 필요하다. 예를 들어, 영어의 어순이 s+v+o에 나타나는 반면에, 한국어의 어순은 s+o+v와 같은 형식으로 나타나게 된다. 이러한 언어마다 annotation이 다를 경우에 cross-lingual transfer (교차언어 변환)과 같은 시도시에 오류가 나타날 수 밖에 없다. 따라서 해당 논문에서는 언어의 Dependency Annotation을 범용적으로 통일하려는 시도가 있었다고 생각한다. 이 부분은 parse tree를 생각해보면 쉽게 이해할 수 있다. 한국어의 parse tree, 영어의 parse tree를 만들 때 있어서 token의 종류에 대해 공통적인 부분을 가질 수 있으나 다른 token의 종류로 인식할 수도 있고, 다른 token의 종류로 분류되어야 함에도 같은 token으로 분류될 수 있다. 이러한 부분을 일관성있게 Dependency Annotation을 진행하였다는 의미다.
해당 분야에 대해 지식이 아직 너무 모자라기에 논문을 이해하는 데 굉장히 힘들었고, 아직 이해하지 못한 부분도 있으나 논문을 한국어로 번역하며 각 문단들을 해석하려고 시도해보았다.
Abstract
We present a new collection of treebanks with homogeneous syntactic dependency annotation for six languages: German, English, Swedish, Spanish, French and Korean. To show the usefulness of such a resource, we present a case study of cross-lingual transfer parsing with more reliable evaluation than has been possible before. This 'universal' treebank is made freely available in order to facilitate research on multilingual dependency parsing.
우리는 총 6가지의 언어를 위한 균일한 구문 의존성 annotation을 가진 treebank의 새로운 collection을 제안한다. (독일어, 영어, 스웨덴어, 스페인어, 불어, 한국어)
* 여기서 treebank란, 파싱된 text corpus를 의미하며, 구문적으로 혹인 문법적으로 annotate된 것을 말한다. 구문 의존성 annotation이란 말 그대로 구문의 위치, 주변 단어들의 뜻 등 parse tree에 따라 의존적으로 annotation이 된 것을 의미한다.
우리는 이러한 annotation의 유용성을 증명하기 위해, 기존에 가능했던 보다 신뢰성있는 평가 방법과 함께 교차-언어 변환의 예시 연구를 제공한다. 이 '범용적' treebank는 다언어 의존성 parsing 연구를 용이하게 하기 위해 무료로 이용될 수 있다.
Introduction
In recent years, syntactic representations based on head-modifier dependency relations between words have attracted a lot of interest. Research in dependency parsing computational methods to predict such representations has increased dramatically, due in large part to the availability of dependency treebanks in a number of languages. In particular, the CoNLL shared tasks on dependency parsing have provided over twenty data sets in a standardized format.
최근에, 단어들 사이에 head-modifier 의존 관계에 기반한 통사론적 표현이 많은 흥미를 끌고 있다.
* head-modifier는 다음과 같은 예시를 생각해볼 수 있다:
the beautiful butterfly => 여기서 the와 beautiful은 modifier가 되고 head는 butterfly가 된다. 즉 수식어를 이끄는 명사들을 의존적 그래프로 나타낼 수 있다는 것이다.
이러한 표현을 예측하는 의존 parsing 계산론적 방법의 연구는 드라마틱하게 증가 되었고, 이는 대부분의 언어로 의존성 treebank를 이용할 수 있다는 점이 큰 이유가 되었다. 특히 dependency parsing을 하는 CoNLL은 Standard화된 형태의 20개가 넘는 dataset을 제공하였다.
* 다양한 언어와 dependency parsing을 전문적으로 하는 곳이 기준화된 dataset을 제공함에 따라 이에 대한 연구가 폭발적으로 증가되었다.
While these data sets are standardized in terms of their formal representation, they are still heterogeneous treebanks. That is to say, despite them all being dependency treebanks, which annotate each sentence with a dependency tree, they subscribe to different annotation schemes. This can include superficial differences, such as the renaming of common relations, as well as true divergences concerning the analysis of linguistic constructions,. Common divergences are found in the analysis of coordination, verb groups, subordinate clauses, and multi-word expressions.
이러한 dataset이 그들의 형식 표현으로 형식화됐음에도 그들은 아직도 이질적인 treebank다. 말하자면, dependency tree와 함께 각각의 문장들이 annotate된 dependency treebank로 존재함에도 그들은 다른 annotation scheme를 갖는다. 이것들은 피상적인 차이를 가져올 수 있는데, 예를 들어 공통된 관계에 새로운 이름을 부여한다던가, 언어적 구성의 분석에 관해서도 큰 차이를 만들어 낼 수 있다. 공통된 차이점은 동등성 분석, 동사 그룹, 종속 조항, 다언어 표현등에서 발견된다.
* 그들의 형식 표현으로 형식화됐음에도 이질적인 treebank를 가진다는 뜻은 같은 annotation을 가져야함에도 언어적 구성같은 차이에 의해 다른 annotation을 가질 수 있다는 것이다.
These datasets can be sufficient if one's goal is to build monolingual parsers and evaluate their quality without reference to other languages, as in the original CoNLL shared tasks, but there are many cases where heterogeneous treebanks are less than adequate. First, a homogeneous representation is critical for multilingual language technologies that require consistent cross-lingual analysis for downstream components. Second, consistent syntactic representations are desirable in the evaluation of unsupervised or cross-lingual syntactic parsers. In the cross-lingual study of McDonal et al., where delexicalized parsing models from a number of source languages were evaluated on a set of target languages, it was observed that the best target language was frequently not the closet typologically to the source. In one stunning example, Danish was the worst source language when parsing Swedish, solely due to greatly divergent annotation schemes.
이러한 dataset은 만약 CoNLL의 shared task처럼, 다른 언어의 reference 없이 단언어 parser를 만들고 그 parser를 평가하는데 목표가 있다면 효과적일 수 있으나, 이질적인 treebank가 적절하지 않은 경우가 더욱 많다. 첫 번째로, 하위 요소를 위한 일관적 cross-lingual 분석을 요구하는 다국어 언어 기술을 위해 균질한 표현은 중요하다. 두 번째로, 일관적 품사론적 표현은 unsupervised나 교차언어 통사론적 parser에 중요하다. McDonald의 cross-lingual 연구에서 여러 소스 언어의 어휘 해제화된 parsing 모델이 대상 언어 집합 평가된 경우, 최적의 대상 언어가 소스와 유형학적으로 가깝지 않은 경우가 많았다. 하나의 충격적인 예시로, 덴마크어는 크게 다른 annotation 스키마에 의해 스웨덴어를 parsing할 때 가장 최악의 언어였다.
In order to overcome these difficulties, some cross-lingual studies have resorted to heuristics to homogenize treebanks (Hwa et al., 2005; Smith and Eisner, 2009; Ganchev et al., 2009), but we are only aware of a few systematic attempts to create homogenous syntactic dependency annotation in multiple languages. In terms of automatic construction, Zeman et al. (2012) attempt to harmonize a large number of dependency treebanks by mapping their annotation to a version of the Prague Dependency Treebank scheme (Hajiˇcet al., 2001; B¨ohmov´a et al., 2003). Additionally, there have been efforts to manually or semimanually construct resources with common syntactic analyses across multiple languages using alternate syntactic theories as the basis for the representation
(Butt et al., 2002; Helmreich et al., 2004; Hovy et al., 2006; Erjavec, 2012).
이러한 어려움들을 극복하기 위해, 몇몇 cross-lingual study는 treebank를 균일하게 하기 위해 heuristics을 재정렬하였다. 그러나 우리는 다양한 언어에서 균질한 통사론적 의존 annotation을 만들기 위한 몇몇의 시스템적 시도만 알고 있다. 자동 구성 관점에서, Zeman은 Prague Dependency Treebank 스키마 버전에 그들의 annotation을 mapping하는 것으로 dependency treebank의 거대한 양을 융화시키려 하였다. 더하여, 그들은 표현의 기초로 대체 구문 이론을 사용하여 다양한 언어 상에 공통된 통사론적 분석과 함께 수동 혹은 반자동적으로 resource를 만들려는 노력을 하였다.
In order to facilitate research on multilingual syntactic analysis, we present a collection of data sets with uniformly analyzed sentences for six languages: German, English, French, Korean, Spanish and Swedish. This resource is freely available and we plan to extend it to include more data and languages. In the context of part-of-speech tagging, universal representations, such as that of Petrov et al. (2012), have already spurred numerous examples of improved empirical cross-lingual systems (Zhang et al., 2012; Gelling et al., 2012; T¨ackstr¨om et al., 2013). We aim to do the same for syntactic dependencies and present cross-lingual parsing experiments to highlight some of the benefits of cross-lingually consistent annotation. First, results largely conform to our expectations of which target languages should be useful for which source languages, unlike in the study of McDonald et al. (2011). Second, the evaluation scores
in general are significantly higher than previous cross-lingual studies, suggesting that most of these studies underestimate true accuracy. Finally, unlike all previous cross-lingual studies, we can report full labeled accuracies and not just unlabeled structural accuracies.
다언어적 통사론적 분석 연구를 용이하게 하기 위해, 우리는 6가지 언어로 균일하게 분석된 문장이 있는 dataset의 collection을 제공한다: 독일어, 영어, 프랑스어, 한국어, 스페인어, 스웨덴어. 이 resource는 자유롭게 이용가능하며, 우리는 보다 많은 data와 언어들을 포함하여 확장시킬 계획이다. 품사 태깅과 관련하여 Petrov가 제안한 보편적인 표현은 이미 개선된 경험적 교차 언어 시스템의 많은 예를 촉진시켰다. 우리의 목표는 통사론적 의존성을 위해 똑같이 행하고, 교차언어적 보편 annotation의 이익의 일부분을 강조시키는 교차언어 parsing 실험을 제안하는 것이다. 첫 번째로, McDonald의 연구 결과와는 달리, 목표언어가 어떤 소스 언어에 유용해야 하는지에 대한 우리의 기대에 부합하다. 두 번째, 일반적으로 평가 점수는 이전의 교차 언어 연구보다 유의미하게 높았으며, 이는 연구의 대부분이 실제 정확도를 과소평가함을 나타낸다. 마지막으로, 모든 교차언어 연구와는 다르게, 우리는 full labeled 정확도와 unlabel 구조적 정확성을 측정할 수 있다.
*여기까지의 내용을 정리해보자. 일단, 문제가 되는 것은 cross-lingual experiment에서 target language가 어떤 source 언어에 유용해야 하는지에 대해 그 결과가 낮았던 이유는 언어간 annotation representation가 달랐기 때문이다. 예를 들어, 한국어의 언어 구성과 영어의 언어 구성은 많이 다르다. 그러나 예를 들어, 한국어의 검색 결과를 통해 영어, 중국어의 웹문서를 가져오려 할 때, 이러한 구문 분석은 필수적이다. 즉 아예 이러한 구문 분석을 할 때, 보편적인 annotation을 쓰면 확실히 정확도를 높일 수 있을 것이란 말이다. 이러한 예시는 두 번째에 나타났듯이, 평가 점수가 이전의 교차 언어 연구보다 유의미하게 높았다는 것에 있다. 일정한 보편적 annotation을 사용했음에도 교차 언어 연구가 유의미하게 평가 점수가 높아졌다는 것이다.
Towards A Universal Treebank
The Stanford typed dependencies for English (De Marneffe et al., 2006; de Marneffe and Manning, 2008) serve as the point of departure for our ‘universal’ dependency representation, together with the tag set of Petrov et al. (2012) as the underlying part-of-speech representation. The Stanford scheme, partly inspired by the LFG framework, has emerged as a de facto standard for dependency annotation in English and has recently been adapted to several languages representing different (and typologically diverse) language groups, such as Chinese (Sino-Tibetan) (Chang et al., 2009), Finnish (Finno-Ugric) (Haverinen et al., 2010), Persian (Indo-Iranian) (Seraji et al., 2012), and
Modern Hebrew (Semitic) (Tsarfaty, 2013). Its widespread use and proven adaptability makes it a natural choice for our endeavor, even though additional modifications will be needed to capture the full variety of grammatical structures in the world’s languages.
영어를 위한 Standford typed dependency는 품사론적 표현으로써, Petrov의 tag set과 더불어 우리의 범용적 의존성 표현을 위한 출발점을 제공한다. LFG framework에 의해 부분적으로 영감을 받은 Stanford 스키마는 영어의 의존성 주석을 위한 사실상의 표준으로 등장했으며 최근에는 다른 언어 그룹을 대표하는 여러 언어에 맞게 수정되었다. (중국어, 프랑스어, 페르시안어, 현재 히브릭어). 그것의 범용적 사용과 증명된 적용성은 세계의 언어에서 다양한 문법 구조를 포착하기 위해서는 추가 수정이 더 필요할 것이다.

We use the so-called basic dependencies (with punctuation included), where every dependency structure is a tree spanning all the input tokens, because this is the kind of representation that most available dependency parsers require. A sample dependency tree from the French data set is shown in Figure 1. We take two approaches to generating data. The first is traditional manual annotation, as previously used by Helmreich et al. (2004) for multilingual syntactic treebank construction. The second, used only for English and Swedish, is to automatically convert existing treebanks, as in Zeman
et al. (2012).
우리는 모든 input token을 걸친 tree가 모든 dependency 구조가 되는 basic depedency를 사용하는데, 그 이유는 이것이 대부분 이용가능한 dependency parser가 요구하는 표현 중 하나이기 때문이다. 하나의 의존 트리가 예시로 나와있다. 우리는 data를 생성하기 위해 두 가지 접근을 한다. 첫 번째는 전통적인 조작 (수동) annotation이며, 다언어 품사론 treebank 구성을 위한 것이다. 두 번째는 영어와 스웨덴어만을 위해 사용된 것이며, 자동으로 나타나는 treebank를 변환하는 것이다.
Automatic Conversion
Since the Stanford dependencies for English are taken as the starting point for our universal annotation scheme, we begin by describing the data sets produced by automatic conversion. For English, we used the Stanford parser (v1.6.8) (Klein and
Manning, 2003) to convert the Wall Street Journal section of the Penn Treebank (Marcus et al., 1993) to basic dependency trees, including punctuation and with the copula verb as head in copula constructions. For Swedish, we developed a set of deterministic rules for converting the Talbanken part of the Swedish Treebank (Nivre and Megyesi, 2007) to a representation as close as possible to the Stanford dependencies for English. This mainly consisted in relabeling dependency relations and, due to the fine-grained label set used in the Swedish Treebank (Teleman, 1974), this could be done with high precision. In addition, a small number of constructions required structural conversion, notably coordination, which in the Swedish Treebank is given a Prague style analysis (Nilsson et al., 2007). For both English and Swedish, we mapped the language-specific part-of-speech tags to universal tags using the mappings of Petrov et al. (2012).
영어를 위한 Stanford 의존성이 우리의 보편적 annotation 스키마를 위한 출발점으로 사용되므로, 우리는 자동 변환을 통해 생성된 dataset을 묘사하는 것으로 시작한다. 영어를 위해 Penn Treebank의 Wall Street Journal 섹션을 기초 의존 트리로 변환하기 위해, 구두점을 포함하여 copula 구성의 head 역할의 copula verb와 함께 Stanford parser를 사용했다. 스웨덴어를 위해, 우리는 스웨덴 treebank의 Talbanken Section을 영어에 대한 Stanford 종속성과 최대한 가까운 표현으로 변환시키기 위한 결정론적 규칙 집합을 개발했다. 이것은 주로 relabeling 의존 관계로 구성되었으며, Swedish Treebank에서 사용된 세밀한 label set으로 인해 고정밀도로 수행된다. 또한 Swedish treebank에서는 프라하 스타일 분석이 주어진 구조변환이 필요한 적은 수의 구조가 필요하다. 영어, 스웨덴어에서 우리는 Petrov의 mapping을 이용하여 언어별 품사태그를 범용 태그에 매핑했다.
* 6개의 언어 중 영어와 스웨덴어는 자동 변환을 이용하여 품사론적 태그를 범용 태그에 매핑한다. 먼저 Stanford Dependency가 기준 즉, 출발점이 되므로 이를 이용하여 Wall Street Journal Section을 Stanford parser를 사용하여 기초 의존 트리로 변환한다. 스웨덴어에서는 수동적 조작없이 relabel dependency 관계로 이를 범용 태그에 매핑한다.
Manual Annotation
For the remaining four languages, annotators were given three resources: 1) the English Stanford guidelines; 2) a set of English sentences with Stanford dependencies and universal tags (as above); and 3) a large collection of unlabeled sentences randomly drawn from newswire, weblogs and/or consumer reviews, automatically tokenized with a rule-based system. For German, French and Spanish, contractions were split, except in the case of clitics. For Korean, tokenization was more coarse and included particles within token units. Annotators could correct this automatic tokenization.
남아있는 네 가지 언어를 위한, annotator는 주어진 3가지 자원을 받는다 : 1) 영어 Stanford guideline, 2) Stanford 의존성과 범용성 태그로 이루어진 영어 문장 set 3) rule based system에 의해 자동적으로 토큰화된 newswire, weblogs, 소비자 review로부터 무작위로 뽑은 unlabeled 문장의 거대한 collection. 독일어, 불어, 스페인어 같은 경우, 수사학은 분열의 경우를 제외하고 분할되었으며, 한국어의 경우, 토큰화가 더욱 조악했고, token unit내에 particle을 포함했다.
The annotators were then tasked with producing language-specific annotation guidelines with the expressed goal of keeping the label and construction set as close as possible to the original English set, only adding labels for phenomena that do not exist in English. Making fine-grained label distinctions was discouraged. Once these guidelines were fixed, annotators selected roughly an equal amount of sentences to be annotated from each domain in the unlabeled data. As the sentences were already randomly selected from a larger corpus, annotators were told to view the sentences in order and to discard a sentence only if it was 1) fragmented because of a sentence splitting error; 2) not from the language of interest; 3) incomprehensible to a native speaker; or 4) shorter than three words. The selected sentences were pre-processed using cross-lingual taggers (Das and Petrov, 2011) and parsers (McDonald et al., 2011).
그 후, Annotator는 label 및 구성 set을 원래 영어 set에 가능한 가깝게 유지하며, 영어로 존재하지 않는 경우, label을 추가하는 목표를 가지고 언어별 annotation guideline을 작성해야 한다. 매우 세밀한 label 구분법을 만드는 것은 장려하지 않았다. 이 guideline이 수정될 때, annotator는 unlabel data의 각각의 domain으로부터 lough하게 annotate하기 위해 같은 양의 문장들을 선택한다. 이러한 문장들이 거대한 corpus로부터 무작위로 이미 선택되면, annotator는 문장을 순서대로 보고 문장을 버리라는 명령을 받는다. 1) 문장이 문장 splitting error에 의해 fragment된 경우 2) 관심있는 언어로부터 온 문장이 아닌 경우 3) native speaker에게 이해할 수 없는 문장인 경우 4) 3개의 단어보다 짧게 이뤄진 경우
이 선택된 문장들은 교차언어 tagger를 이용하여 전처리된다.
The annotators modified the pre-parsed trees using the TrEd2 tool. At the beginning of the annotation process, double-blind annotation, followed by manual arbitration and consensus, was used iteratively for small batches of data until the guidelines were finalized. Most of the data was annotated using single-annotation and full review: one annotator annotating the data and another reviewing it, making changes in close collaboration with the original annotator. As a final step, all annotated data was semi-automatically checked for annotation consistency.
그 annotator는 TrEd tool을 이용하여 pre-parsed tree를 수정했다. annotation 과정의 시작에서, guideline이 완료될 때 까지 작은 batch를 위해 반복적으로 수동 arbitration과 consensus (중재와 합의)에 이은 이중 blind annotation이 사용되었다.
* double blind annotation은 tester와 subject가 모두 blind된 경우를 뜻한다.
대부분의 data는 single-annotation과 full review를 사용하여 annotate되었다: 하나의 annotator가 data를 annotate하고, 또 다른 annotator가 그것을 review하고, 원래의 annotator로 유사한 collaboration 형태로 수정한다. 마지막으로, 모든 annotate된 data가 반자동적으로 annotation 일관성이 있나 확인된다.
Harmonization
After producing the two converted and four annotated data sets, we performed a harmonization step, where the goal was to maximize consistency of annotation across languages. In particular, we wanted to eliminate cases where the same label was used for different linguistic relations in different languages and, conversely, where one and the same relation was annotated with different labels, both of which could happen accidentally because annotators were allowed to add new labels or the language they were working on. Moreover, we wanted to avoid, as far as possible, labels that were only used in one or two languages.
두 개의 변환된, 그리고 4개의 annotate된 data set을 생성하고선, 우리는 언어적으로 annotation의 일관성을 최대화하는 목표를 위해 융화 작업을 거친다. 특히, 서로 다른 언어에서 다른 언어적 관계를 위해 같은 label이 사용된 경우를 제거하고, 반대의 경우, 하나 혹은 동일한 관계가 다른 label로 annotate된 경우를 제거하기를 원한다. 두 경우 모두 annotator가 작동하는 언어에서 새로운 label을 추가할 때 실수로 일어날 수 있다. 또한, 가능한 한 두 언어로만 사용되는 언어로만 사용되는 label은 피하려 하였다.
In order to satisfy these requirements, a number of language-specific labels were merged into more general labels. For example, in analogy with the nn label for (element of a) noun-noun compound, the annotators of German added aa for compound adjectives, and the annotators of Korean added vv for compound verbs. In the harmonization step, these three labels were merged into a single label compmod for modifier in compound.
이러한 요구사항을 만족시키기 위해, 언어 특화정 label의 숫자가 보다 일반화된 label로 융합되었다. 예를 들어 언어학에서 명사-명사 compound의 nn label와 함께 독일어 annotater에서 compound 형용사를 위한 aa를 더했고, 한국어 annotator는 동사 compound를 위해 vv를 더했다. 융화 단계에서 이러한 세 개의 label은 compound에서 수식어로서, 하나의 label인 compmod로 융합되었다.
*이 부분이 이 논문을 이해시키는 데에 결정적인 역할을 하는 예시이다. 언어학에서 다른 annotation을 띤다는 것은 결국 다른 언어 구성 체계를 갖고 있기 때문이다. 다른 언어 구성 체계를 갖고 있기 때문에 교차 언어 작동시에 언어 구성에 어려움을 가지고 있었고, 이를 해결하고자 보편성을 띠는 annotation을 구성하려 했던 것이다.
In addition to harmonizing language-specific labels, we also renamed a small number of relations, where the name would be misleading in the universal context (although quite appropriate for English). For example, the label prep (for a modifier headed by a preposition) was renamed adpmod, to make clear the relation to other modifier labels and to allow postpositions as well as prepositions. We also eliminated a few distinctions in the original Stanford scheme that were not annotated consistently across languages (e.g., merging complm with mark, number with num, and purpcl with advcl).
언어 특성화적 label을 융화시키는 것에 더해, 우리는 또한 범용 context 상에서 오해를 불어일으킬만한 name을 갖고 있는 relation의 일부분에 이름을 재부여하였다. (영어는 아주 적당하지만). 예를 들어, label prep (앞 포지션에 위치하는 수식어)는 adpmod로 수정되었는데, 이는 preposition과 같이 postposition (뒤 포지션에 위치하는, 은/는, 이/가와 같은)을 허락하고, 다른 수식어 label과의 관계를 명확히 하려고 한 것이다. 우리는 또한 원래 Stanford 체계에서 언어마다 일관되게 주석되지 않은 몇 가지 차이들을 제거했다. (ex) mark와 complm의 merge, num과 number, advcl과 purpcl.
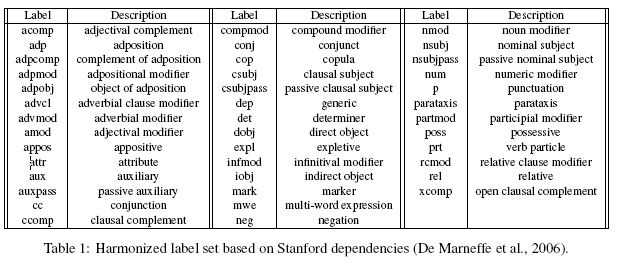
The final set of labels is listed with explanations in Table 1. Note that relative to the universal part-of-speech tagset of Petrov et al. (2012) our final label set is quite rich (40 versus 12). This is due mainly to the fact that the the former is based on deterministic mappings from a large set of annotation schemes and therefore reduced to the granularity of the greatest common denominator. Such a reduction may ultimately be necessary also in the case of dependency relations, but since most of our data sets were created through manual annotation, we could afford to retain a fine-grained analysis, knowing that it is always possible to map from finer to coarser distinctions, but not vice versa.
label의 최종 set은 Table 1에 설명과 함께 있다. Petrov의 보편적 품사 태그 set에 비해, 우리의 최종 set은 꽤 풍부하다. (40 vs 12) 이것은 주로 전자가 많은 양의 annotation 스키마 set으로 부터 결정론적 mapping에 기반되어 있으므로 최대 공통 분모의 세분성으로 축소되었기 때문에 발생한다.
* 이 부분을 이해하는 데 굉장히 어려웠으나, 내 해석에 의하면, 각 annotation 스키마 set들의 최대 공통 분모로만 mapping 되었기 때문에 Petrov의 set이 적다는 것을 의미하는 것 같았다.
이러한 감소는 궁극적으로 의존성 관계 경우에 필수적일 수 있지만, 우리의 dataset의 대부분은 수동 조작을 통해 생성되었기에, 미세한 분석을 유지할 수 있었다. 더 세밀한 분류에서 더 거친 분류로 매핑하는 것은 항상 가능하지만 그 반대는 아니다.
* 작은 양의 set 종류에서 거대한 양의 set 종류로 분류하는 것은 불가능하지만, 거대한 양의 set 종류에서 작은 양의 set 종류로 mapping하는 것은 가능하다. 즉 cross-lingual 측면에서 거대한 양의 set 종류가 항상 유리하다고 말하고 있다.
Final Data Sets
Table 2 presents the final data statistics. The number of sentences, tokens and tokens/sentence vary due to the source and tokenization. For example Korean has 50% more sentences than Spanish, but 40k less tokens due to a more coarse-grained tokenization. In addition to the data itself, annotation guidelines and harmonization rules are included so that the data can be regenerated.
Table 2는 최종 data 통계를 제공한다. 문장, token, token/문장의 양은 source와 tokenization에 따라 다양하다. 예를 들어, 한국어는 스페인어보다 50% 가량 많은 문장을 갖고 있으나, 4만개 정도 적은 token을 가지는 데, 이는 거친 tokenization에 의한 것이다. data 자체와 더해 annotation guideline과 융화 rule은 포함되어 있어 data가 재생성될 수 있다.
Experiments
One of the motivating factors in creating such a data set was improved cross-lingual transfer evaluation. To test this, we use a cross-lingual transfer parser similar to that of McDonald et al. (2011). In particular, it is a perceptron-trained shift-reduce parser with a beam of size 8. We use the features of Zhang and Nivre (2011), except that all lexical identities are dropped from the templates during training and testing, hence inducing a ‘delexicalized’ model that employs only ‘universal’ properties from source-side treebanks, such as part-of-speech tags, labels, head-modifier distance, etc.
dataset을 생성하는 데에 있어 동기 부여 중 하나는 향상된 교차 언어 평가였다. 이것을 test해보기 위해, 우리는 McDonald의 것과 유사한 교차언어 변환을 사용했다. 특히, 그것은 size 8짜리 beam이 있는 훈련된 perceptron shift reduce parser이다. 우리는 Zhang과 Nivre의 feature를 사용한다. 단, training과 test 중에는 모든 어휘 정체성이 templete에서 제외되므로, 품사 태그, label, head-수식어 거리와 같은 source-side treebank로부터 오직 보편적인 특성만 사용하는 delexicalized model을 포함하는 모델이다.
We ran a number of experiments, which can be seen in Table 3. For these experiments we randomly split each data set into training, development and testing sets. The one exception is English, where we used the standard splits. Each row in Table 3 represents a source training language and each column a target evaluation language. We report both unlabeled attachment score (UAS) and labeled attachment score (LAS) (Buchholz and Marsi, 2006). This is likely the first reliable cross-lingual parsing evaluation. In particular, previous studies could not even report LAS due to differences in treebank annotations.
우리는 여러 번의 실험 끝에 Table 3과 같은 결과를 얻었다. 이러한 실험들을 위해, 우리는 무작위로 dataset을 training, develop, test set으로 나누었다. 우리가 기준 split으로 이용한 영어는 제외했다. Table 3의 각 row는 source training 언어를 말하고 각 column은 target 평가 언어를 의미한다. 우리는 unlabeled attachment score와 labeled attachment score를 보괬다. 이것은 첫번째 신뢰가능한 교차언어 평가 방식과 유사하다. 특히, 이전 연구는 treebank annotation의 차이에 의해 LAS를 보고할 수 없다는 문제점이 있다.
We can make several interesting observations. Most notably, for the Germanic and Romance target languages, the best source language is from the same language group. This is in stark contrast to the results of McDonald et al. (2011), who observe that this is rarely the case with the heterogenous CoNLL treebanks. Among the Germanic languages, it is interesting to note that Swedish is the best source language for both German and English, which makes sense from a typological point of view, because Swedish is intermediate between German and English in terms of word order properties. For Romance languages, the crosslingual parser is approaching the accuracy of the supervised setting, confirming that for these languages much of the divergence is lexical and not structural, which is not true for the Germanic languages. Finally, Korean emerges as a very clear outlier (both as a source and as a target language), which again is supported by typological considerations as well as by the difference in tokenization.
우리는 흥미로운 관찰을 할 수 있었다. 눈에 띄는 것은, Germanic과 Romance 타겟 언어에 대해 최고의 source 언어는 같은 언어군으로부터 온 것이라는 것이다. 이것은 McDonald의 결과와 매우 대조적이다. 그는 이종 CoNLL treebank의 경우는 드물다고 관찰했기 때문이다. Germanic 언어 중에서, 스웨덴어가 단어 순서 특성 측면에서 독일어와 영어의 중간이기 때문에 유형론적 관점에서 최고의 source 언어이다. Romance 언어의 경우, 교차 언어 parser가 supervised setting의 정확성을 측정하면, Germanic 언어와는 달리 이러한 언어들 대부분의 차이가 구조적이지 않고 어휘적이다. 마지막으로 한국어는 target과 source 언어로서 매우 명확한 극단치인데, 이러한 사실은 다시 한번 토큰화에서 나타나는 차이점과 유형론적 고려사항에 의해 뒷받침된다.
With respect to evaluation, it is interesting to compare the absolute numbers to those reported in McDonald et al. (2011) for the languages common to both studies (DE, EN, SV and ES). In that study, UAS was in the 38–68% range, as compared to 55–75% here. For Swedish, we can even measure the difference exactly, because the test sets are the same, and we see an increase from 58.3% to 70.6%. This suggests that most cross-lingual parsing studies have underestimated accuracies.
평가와 관련하여 McDonal 등이 보고한 수치와 절대 수치를 비교하는 것은 흥미롭다. 그 연구에서는 UAS는 38~68% 범위이며, 55~75% 범위와 비교되었다. 스웨덴어의 경우 test set이 동일하고 차이가 58.3%에서 70.6%로 증가하기 때문에 정확한 차이를 볼 수 있었다. 이것은 대부분의 교차 언어 구문 분석 연구가 과소평가된 정확도를 가졌다는 것이다.
Conclusion
We have released data sets for six languages with consistent dependency annotation. After the initial release, we will continue to annotate data in more languages as well as investigate further automatic treebank conversions. This may also lead to modifications of the annotation scheme, which should be regarded as preliminary at this point. Specifically, with more typologically and morphologically diverse languages being added to the collection, it may be advisable to consistently enforce the principle that content words take function words as dependents, which is currently violated in the analysis of adpositional and copula constructions. This will ensure a consistent analysis of functional elements that in some languages are not realized as free words or are not obligatory, such as adpositions which are often absent due to case inflections in languages like Finnish. It will also allow the inclusion of language-specific functional or morphological markers (case markers, topic markers, classifiers, etc.) at the leaves of the tree, where they can easily be ignored in applications that require a uniform cross-lingual representation. Finally, this data is available on an open source repository in the hope that the community will commit new data and make corrections to existing annotations.
우리는 일관성있는 의존성 annotation을 사용한 6개 언어에 대한 dataset을 제공했다. 처음 출시된 후에는 더 많은 언어로 데이터에 annotate를 하고 추가 자동 treebank 전환을 조사할 것이다. 이는 또한 annotation 스키마의 수정을 요구할 수 있으며, 이 시점에서 이것은 임시로만 간주되어야 한다. 특히, 더 많은 형식학적 및 형태론적으로 다양한 언어가 collection에 추가된다면, context 단어가 종속적으로 기능적 단어를 수반하는 원칙을 지속적으로 수행하는 것이 좋은데, 이 종속적 단어는 명제 및 공동 작성법 분석에서 위반되었다.
* 솔직히 이 부분이 해석적으로 이해가 안 간다.
이렇게 되면 일부 언어에서는 자유 단어 또는 필수 조건이 아닌 기능 요소에 대한 일관된 분석이 필요하다. (예시로 핀란드어와 같은 언어의 경우 굴곡때문에 종종 부재하는 경우) 또한 트리의 leaf에 언어별 기능적 또는 형태학적 마커 포함이 가능하다. (사례 마커, 분류기, 주제 마커 등) 이 마커는 균일한 교차 언어 표현이 필요한 응용 문야에서 쉽게 무시될 수 있는 부분이다. 마지막으로, 이 data는 새로운 data를 commit하고 기존 annotation을 수정하기를 희망하는 open source 저장소에서 사용할 수 있다.
Comment
해당 논문은 SWRC에서 신입생들을 위한 guideline 논문이다. 일단 이 논문에서 설명하는 것은 다언어에 대한 보편적 annotation의 필요성과 그를 어떻게 만들었는가에 대한 설명이다.
먼저, 풍부한 dataset 종류는 이 논문의 장점이다. 확실히 cross lingual 분야에서 여러 언어 간 transfer가 유의미할 경우 훨씬 더 세밀한 transfer를 이룰 수 있을 것이다.
또한 공통된 annotation을 통해 언어 구성의 보편성을 유지할 수 있다는 것은 장점이다.
하지만, 내가 해석하기에 이 논문에는 문제점이 꽤 있다. 먼저, 영어, 스웨덴어를 제외한 4가지의 언어들을 직접 annotation해야 한다는 점. 이는 native-speaker의 필요성과 더불어, 우리가 input token을 얻어낼 때에 data 수 자체가 적다는 것을 의미할 수 있다. 즉 data의 부족이 수동으로 data를 조작해야하는 귀찮음을 수반해야한다는 것이다.
또한, 한국어와 같은 postposition과 같이 unique한 언어적 구성이 있을 경우 tokenization에 있어 어려움을 겪는다. 그 결과는 낮은 평가 점수로 나타나게 된다.
그래서 이 논문은 결국 박사님이 신입생들에게 자동화 annotation의 중요성, dependency tree construction의 중요성을 말하고, 한국어가 이 부분에 있어 크게 조악한 tokenization을 갖고 있으니 이러한 부분에 연구가 필요하다는 것을 말씀하고 싶어한다는 것 같다.
물론 내 개인적인 의견이고, 논문을 내 마음대로 이해해버린 경향이 없지 않아 있는데, 이 논문에 대해 간략히 주관적으로 설명해주시는 분이 있다면 꼭 그 분의 의견을 듣고 싶다.
오늘의 논문 정리 끄읕~~
참고로 모든 figure는 논문에 있는 figure를 가져다 사용하였습니다.
답글삭제