JM5) Spelling Correction and the Noisy Channel
Spelling Correction and the Noisy Channel
이번 챕터에서는 스펠링 에러를 탐지하고 보정하는 문제에 대해 다루고자 한다. 스펠링 에러를 고치는 것은 현대 세계에서 쓰는 데에 있어서 중요한 부분인데, 쓰기 부분이라 함은 핸드폰을 통해 문자 메시지를 보내는 것일수도 있고 이메일을 보내는 것일 수도 있으며, 긴 문서를 작성하거나 웹 상에 정보를 찾아보는 것도 포함한다. 현대 스펠링 보정기는 완전하지는 않지만, 키보드의 인풋에 의존하는 소프트웨어들이라면 어디에나 있음직하다.
스펠링 보정은 두 가지의 전망으로부터 고려된다. 단어가 아닌 스펠링 보정은 결과적으로 단어가 아니게 되는 스펠링 에러를 탐지하고 보정하는 일이다. (예를 들어, 기런이라는 단어는 없지만 기린과 유사해보인다.) 이와 대조적으로 현실 세계 스펠링 보정은 그 스펠링 에러가 결과적으로 영어의 현재 단어를 나타내어도 그 에러를 탐지하고 보정하는 것이다. (real-word errors) 예를 들어, 인쇄상의 오류로 인해 이루어질 수 있는데, 실제 단어를 유연히 생성하는 there for three라던가 동음이의어(cognitive errors)로 인한 dessert for desert, piece for peace와 같은 단어들이 존재하겠다.
단어가 아닌 에러(Non-word Errors)는 사전으로부터 발견되지 않은 단어를 보는 것으로 탐지된다. 예를 들어 잘 못 스펠링된 graffe와 같은 경우에는 dictionary에 발견되지 않는다. 보다 거대한 dictionary가 더 좋다고 말할 수 있다. 현대 시스템에는 종종 web으로부터 유도된 거대한 사전을 사용하기도 한다. 단어가 아닌 에러를 보정하기 위해 첫 번째로 후보자들(candidates)들을 생성한다: 실제 단어는 에러와 유사한 문자 서열을 가지고 있다. 스펠링 에러로부터 후보자 보정에서 graffe같은 경우에는 giraffe, graf, gaffe, grail 혹은 craft와 같은 후보자들이 있다. 우리는 소스와 표면 에러 사이로부터 distance metric을 구하고 이를 사용하여 후보자들에게 순위를 매긴다. 우리는 graffe라는 non-word error에 대하여 giraffe가 보다 수정되어야 할 단어라고 추측하는데, giraffe가 grail보다 graffe라는 non-word error에 대해 유사한 폼을 가지고 있기 때문이다. 챕터 2의 minimum edit distance algorithm은 여기서 이를 위한 역할을 수행한다. 그러나 우리는 또한 보다 빈도수가 많은 단어나 error의 context에 보다 나옴직한 단어들로 보정하는 것도 선호하기도 한다. 다음 섹션의 noisy channel model은 이러한 추측을 형태화시키는 방법을 제공한다.
실제 단어 스펠링 에러(real word spelling error) 탐지는 더욱 더 어려운 작업이다. 아직, 유저에 의해 입력된 각 단어 w에 대해 후보자들을 찾는 noisy channel을 사용하거나 유저의 원래 의향대로 있음직한 보정을 순위를 매기는 것은 가능하긴 하다.
Noisy Channel Model
이번 섹션에서는 noisy channel model을 소개하고 이것을 스펠링 에러를 탐지하고 보정하는 데에 있어 어떻게 적용되는지 살펴보겠다. Noisy channel model은 AT&T Bell Laboratory와 IBM Watson Research의 연구자들이 동시간데에 스펠링 보정을 적용시킨 모델이다.
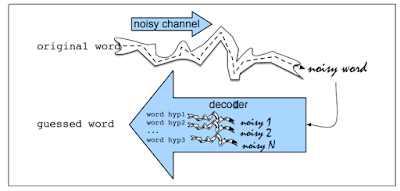
noisy channel model의 추측은 만약 옳게 스펠링된 단어가 noisy communication channel에 의해 왜곡되었을때, 잘못 스펠링된 단어를 다루는 것이다.
그 channel은 "진짜" 단어를 인지하기 어렵게 만드는 단어의 변형의 형태로 "noise"를 제공한다. 그러므로, 우리의 목표는 이러한 channel의 model을 만드는 것이다. 주어진 모델에 대해 우리는 noisy channel의 우리의 모델을 언어의 모든 단어를 통과시키는 것으로 진짜 단어를 찾고 잘못 스펠링된 단어와 가장 가까운 단어를 찾는 것이다.
그 noisy channel model은 Bayesian inference의 한 일종이다. 잘못 스펠링된 단어인 관찰 x를 보고, 우리의 작업은 이러한 잘못 스펠링된 단어를 생성시키는 단어 w를 찾는 것이다. 사전 V에서 P(w|x)가 가장 높게 나타나는 모든 가능한 단어 w들을 찾길 원한다. 우리는 hat notation ^을 옳은 단어 우리의 추측을 의미하는데 사용한다.
$$ \hat{w} = argmax_{w\in V} P(w|x) $$
함수 $argmax_{x}f(x)$는 $f(x)$값을 최대화 시키는 $x$를 의미한다. 위의 식은 그러므로 사전에서 나타나는 모든 단어들에서, 우리는 우변식 $P(w|x)$를 최대화시키는 특정 단어를 찾는다는 것이다.
Bayesian Classification의 추측은 다른 확률의 set으로 Bayes' rule을 이용하여 식을 변형시키는 것이다. Bayes' rule은 아래의 식에 설명되어 있다. 그것은 하나의 조건부 확률 $P(a|b)$를 다른 세가지의 확률로 분해하는 방법을 제공한다:
$$P(a|b) = \frac{P(b|a) P(a)}{P(b)}$$
우리는 두 가지의 식을 합쳐 다음과 같은 식을 유도할 수 있다:
$$\hat{w} = argmax_{w\in V} \frac{P(x|w)P(w)}{P(x)} $$
우리는 편리하게 이 식에서 denominator P(x)를 제거하는 것으로 간단화시킬 수 있다. 이것이 가능한 이유는 모든 단어에서 가능성있는 보정 단어를 선택할 때 우리는 각 단어의 $\frac{P(x|w)P(w)}{P(x)}$를 계산한다. 하지만 P(x)는 각 단어들에서 변하지 않는다. 우리는 항상 관찰된 에러 x에 대해 있음직한 단어를 알아보기 때문에 P(x)에 대해 같은 확률을 가진다. 그러므로 우리는 보다 더 간단해진 형태를 최대화 시키는 단어를 선택하면 된다:
$$\hat{w} = argmax_{w\in V} P(x|w)P(w) $$
요약하면, noisy channel model은 우리가 진정한 기본 단어 w를 가지고 있다고 말하며, 우리는 가능성있는 잘못 스펠링됭 표면형으로 단어를 수정시키는 noisy channel을 가지고 있다는 것이다. 그 특정 관찰 서열 x를 생성하는 noisy channel의 likelihood 혹은 channel model은 P(x|w)에 의해 모델링된다. 이 때 prior P(w)와 likelihood P(x|w)를 곱하고 그 곱이 가장큰 단어를 선택하는 것으로 관찰된 잘못 스펠링된 x를 보는 것으로 hidden word의 prior probability는 P(w)에 의해 모델링된다. 우리는 가장 유망한 후보자 단어 $\hat{w}$를 계산한다.
우리는 우리의 스펠링 사전에서 나타나지 않는 단어를 찾고 후보자 단어의 리스트를 작성하고, 그것들에 순위를 매기고 가장 순위가 높은 단어를 선택하는 것으로 단어가 아닌 스펠링 에러를 보정하는 것으로 noisy channel 접근 방법을 사용한다. 우리는 식을 전체 사전 V 대신에 후보자 리스트들을 참조함으로 수정할 수 있다.
$$ \hat{w} = argmax_{w\in C} P(x|w)P(w) $$
이 때 P(x|w)는 channel model이고 P(w)는 prior이다. likelihood와 prior를 계산하기 위한 detail을 보기위해 예시를 살펴보자.

알고리즘의 첫번째 단계는 단어를 찾는 것으로 input word와 유사한 spelling을 가진 단어 후보자들을 보는 것이다. 스펠링 에러 데이터의 분석은 각 문자를 구성하는 spelling error를 보고 그러므로 우리는 error word로부터 후보자들이 1의 edit distance만 갖는다고 간단한 추측을 할 수 있다. 우리는 Chapter 2에서 소개된 minimum edit distance algorithm을 사용할 것이지만 후보자 리스트를 찾기 위해 insertion deletion 그리고 substitution에 대해 확장된 버전인 transposition이라는 한 가지 형태를 더 추가한다. transposition 형태가 추가된 edit distance version은 Damerau-Levenshtein edit distance라 불린다.
 우리가 이러한 후보자들의 세트를 가질때는, 각각의 scoring하기 위해 channel model과 prior를 계산하여야 한다.
우리가 이러한 후보자들의 세트를 가질때는, 각각의 scoring하기 위해 channel model과 prior를 계산하여야 한다.
각 보정값 P(w)의 prior 확률은 context에서 단어 w가 나타나는 언어 모델 확률인데, 이는 unigram부터 trigram 혹은 4-gram으로부터 어떠한 언어 모델을 사용하여 계산될 수 있다. 예시를 통해 unigram 언어 모델을 시작해보자. 우리는 Corpus of Contemporary English (COCA)의 단어 404,253,213개로부터 언어 모델을 계산하였다.
 우리는 어떻게 likelihood P(x|w), channel model 혹은 error 모델이라고도 불리는 것을 추측할 수 있을까? 단어가 잘못입력될 확률의 완벽한 모델은 factor들의 모든 정렬방식을 따르는 것이다: 입력자가 누구인지, 입력자가 왼손 잡이인지 오른손 잡이인지와 같은 factor들 말이다. 운이 좋게도 우리는 local context를 바라보는 것으로 P(x|w)를 논리적으로 추측할 수 있다: 보정된 문자의 특성, 잘못 스펠링된 문자, 그리고 주위의 문자를 통해서 말이다. 예를 들어 문자 m과 n은 때때로 서로 치환된다; 이것은 그들의 특성에 의해 발생되는 사실이다. (이 두 문자는 발음도 비슷한 데에다가, 키보드에 서로 옆에 붙어 있다) 그리고 context상에서도 나타나는 사실이다. (왜냐하면 그들의 유사한 context에서 등장하기 때문)
우리는 어떻게 likelihood P(x|w), channel model 혹은 error 모델이라고도 불리는 것을 추측할 수 있을까? 단어가 잘못입력될 확률의 완벽한 모델은 factor들의 모든 정렬방식을 따르는 것이다: 입력자가 누구인지, 입력자가 왼손 잡이인지 오른손 잡이인지와 같은 factor들 말이다. 운이 좋게도 우리는 local context를 바라보는 것으로 P(x|w)를 논리적으로 추측할 수 있다: 보정된 문자의 특성, 잘못 스펠링된 문자, 그리고 주위의 문자를 통해서 말이다. 예를 들어 문자 m과 n은 때때로 서로 치환된다; 이것은 그들의 특성에 의해 발생되는 사실이다. (이 두 문자는 발음도 비슷한 데에다가, 키보드에 서로 옆에 붙어 있다) 그리고 context상에서도 나타나는 사실이다. (왜냐하면 그들의 유사한 context에서 등장하기 때문)
예를 들어 간단한 모델은 추측한다, p(acress|across)가 그저 에러의 거대한 corpus에서 letter o가 letter e로 치환된 빈도수를 세는 것이라고. 이러한 방법을 통해 확률을 계산하기 위해서는 우리는 error의 빈도수를 세는 confusion matrix를 요구한다. 일반적으로, confusion matrix는 또 다른 단어와 혼동하였을 때의 빈도수를 나열한다. 그러므로 예를 들어 substitution matrix는 26*26 사이즈의 정사각행렬로 묘사되는데, 이는 하나의 문자가 또 다른 문자로 옳지 않게 사용된 빈도수를 체크한다. 우리는 4개의 confusion matrix를 사용할 것이다.
del[x,y]: count(xy typed as x)
ins[x,y]: count(x typed as xy)
sub[x,y]: count(x typed as y)
trans[x,y]: count(x typed as yx)
다음의 것들을 이러한 것의 한 예시이다:
additional: addional, additonal
environments: enviornments, enviorments, enviroments
preceded: preceeded
...
이러한 list는 Wikipedia와 Roger Mitton 그리고 Peter Norvig에서 이용가능하다. Norvig는 또한 각각의 싱글 문자열의 빈도수를 제공하는데, 이는 바로 에러 모델 확률을 만들 수 있다.
Kernighan et al.에 의해 제안된 접근 방법은 이 스펠링 에러 보정 알고리즘을 반복적으로 그것의 행렬값을 계산하는 것이다. 이 반복적인 알고리즘은 처음에는 같은 값으로 행렬을 시작하는데, 이는 어느 문자든 동일하게 삭제될 수 있으며, 동일하게 다른 문자와 치환될 수 있음을 뜻한다. 다음은 스펠링 에러 보정 알고리즘은 스펠링 에러의 세트에서만 작동한다. 그들의 예측된 보정과 함께 페어링된 오타들의 주어진 세트에서 confusion 행렬은 다시 재계산되고, 스펠링 알고리즘은 다시 작동하는 방식이다. 이러한 반복 알고리즘은 중요한 EM 알고리즘의 표본이다.
우리가 confusion matrix를 가지고 있을때 우리는 다음과 같이 P(x|w)를 예측하고 ($w_i$는 올바른 단어 w의 i-th 문자열이다) 그리고 $x_i$는 오타 x의 i-th 문자열이다.
$$P(x|w) = \begin{cases} \frac{\text{del}[x_{i-1}, w_i]}{\text{count}[x_{i-1}w_i]}, & \text{if deletion} \\ \frac{\text{ins}[x_{i-1}, w_i]}{\text{count}[w_{i-1}]}, & \text{if insertion} \\ \frac{\text{sub}[x_i, w_i]}{\text{count}[w_i]}, & \text{if substitution} \\ \frac{\text{trans}[w_i, w_{i+1}]}{\text{count}[w_iw_{i+1}]}, & \text{if transposition} \end{cases} $$
Kernighan et al.를 참조한 빈도수를 사용한 결과는 다음과 같다.

아래의 그림은 각 가능성있는 보정형태의 최종 확률을 보여준다; unigram prior는 likelihood에 의해 곱해진다. 마지막 column은 가독성을 위해 10의 9승을 곱하였다.

Figure 5.5의 계산은 noisy channel 모델의 우리의 implementation이 최고의 보정으로 across를 선택한다는 것이고, 두 번째로는 actress를 선정한다는 것이다.
공교롭게도 여기의 알고리즘은 옳지 못하다. 왜냐하면 작가의 의도가 맥락에서 명확히 전달되는 경우가 있기 때문이다: ... was called a "stellar and versatile acress whose combination of sass and glamour has defined her... ". 주위의 단어들은 actress가 across보다 명확한 단어임을 말해준다.
이러한 이유로, unigram보다 거대한 언어 모델을 사용하는 것이 중요하다. 예를 들어 만약 우리가 Corpus of Contemporary American English를 단어 actress와 across에서 add-one smoothing을 사용해 bigram 확률을 계산한다면, 우리는 다음과 같은 확률을 얻을 수 있다:
P(actress|versatile) = .000021
P(across|versatile) = .000021
P(whose|actress) = .0010
P(whose|across) = .000006
그렇다면 이 식을 곱하면 다음과 같은 식을 얻을 수 있다.
P("versatile actress whose") = .000021 * .0010 = 210 * 10^(-10)
P("versatile across whose") = .000021 * .000006 = 1 * 10^(-10)
Figure 5.5의 error model과 함께 언어 모델을 결합하여 bigram noisy channel model은 현재 올바르게 보정된 단어인 actress를 선택한다.
Real-word spelling errors
그 noisy channel 접근 방법은 또한 real-word spelling error를 탐지하고 수정하는데 적용될 수 있는데, 이는 영어의 실제 단어들에서 나타나는 에러를 뜻한다. 이것은 인쇄상의 에러로부터 일어날 수 있으며 (insertion, deletion, transposition) 우연치않게 실제 단어를 생성하거나 글쓴이가 동음이의어나 동음이의어에 가까운 것들을 잘못 스펠링하였을 때 나타나는 현상이다.
noisy channel은 또한 real-word 에러를 다룰 수 있다. 이 real-word spelling error를 다루기 위한 Mays et al의 처음 제안한 noisy channel model을 살펴보자. 그들의 알고리즘은 input sentence $X = {x_1, x_2, ..., x_k, ..., x_n}$를 사용하여 후보자 보정 문장 C(x)의 거대한 세트를 생성하고 가장 최고로 높은 언어 모델 확률의 문장을 선택한다.
후보자 보정 문장을 생성하기 위해 우리는 각 input word인 $x_i$에 대하여 후보자 단어를 생성하는 것으로 시작한다. 후보자 $C(x_i)$는 $x_i$로부터의 작은 edit distance와 함께 모든 영어 단어를 포함한다. edit distance 1은, thew라는 real word에 대해 다음과 같은 후보군이 생성된다. C(thew) = {the, thaw, threw, them, thwe}. 우리는 그 후에 오직 하나의 에러만을 갖는 모든 문장을 갖는 다는 간단한 추측을 한다. 그 후에 후보 문장 C(X)에 대하여 문장 X = Only two of thew apples는 다음과 같다:
only two of thew apples
oily two of thew apples
only too of thew apples
only to of thew apples
only tao of the apples
only two on thew apples
only two off thew apples
only two of the apples
only two of threw apples
only two of thew applies
only two of thew dapples
...
각각의 문장들은 noisy channel에 의해 scoring된다:
$$\hat{W} = argmax_{W\in C(X)} P(X|W) P(W) $$
P(w)를 위해 우리는 문장의 trigram 확률을 사용할 수 있다.
channel model은 어떠한가? 이러한 real word에 의하여 우리는 input word가 error가 아닐 확률을 고려해야만 한다. 단어를 작성하는 것의 channel 확률인 P(w|w)를 $\alpha$로 생각하자.
$$p(x|w) = \begin{cases} \alpha & \text{if } x = w \\ \frac{1-\alpha}{|C(x)|} & \text{if } x \in C(x) \\ 0 & \text{otherwise} \end{cases} $$
이제 우리는 모든 보정에 대한 $1-\alpha$의 같은 분포를 대체할 수 있다. 우리는 confusion matrix를 사용하는 Eq. 5.6으로부터 보다 복잡한 channel model인 edit probability에 비례하는 분포를 만들 것이다.
실제 단어에 적용된 이 통합된 noisy channel noisy의 예시를 바라보자. 우리가 문자열인 two of thew를 본다고 생각하자. 작성자는 아마 실제 단어 thew를 입력하기로 예정했다고 하자. 하지만 thew는 여기서 또한 the나 다른 단어로 오타가 날 수 있다. 이러한 예시의 목적을 위해 edit distance 1인 것들을 고려하고, 다섯 개의 후보군 the, thaw, threw 그리고 thwe와 입력된 thew를 고려해보자. 우리가 이 예시에서 Norvig의 edit 확률을 사용할 것이다. 언어 모델 확률을 위해 우리는 Stupid Backoff model을 사용하였다:

여기서 우리는 그저 기본형태의 구인 two of thew의 확률을 구하였지만, 모델은 전체 문장에 대해 적용한다. 그래서 만약 문맥에서의 예시가 two of thew people 이였다면, 우리는 또한 P(people|of the)나 P(people|of thew), P(people|of threw)와 같은 확률을 곱해주어야만 한다.

Noisy Channel Model: The State of The Art
noisy channel spelling correction의 최첨단 구현은 우리가 위에서 제공했던 간단한 모델의 확장 버전이다.
첫 번째로, 입력 문장이 오직 single error만 가지고 있다는 추측을 만드는 것보다 현재 시스템에서는 제 때에 입력 하나의 단어를 통해 살펴보고 그 단어에 대해 noisy channel을 이용하여 결정권을 내린다. 그러나 우리가 각 단어에 대하여 묘사된 기본 noisy channel system을 작동하기 위해서는 그것은 정확하지만 희귀한 단어를 보다 빈번한 단어로 대체하여 과보정(overcorrecting)하는 경우가 많다. 현대 알고리즘은 그러므로 실제 단어가 실제로 옳은지 아닌지를 판단하는 방법들과 함께 noisy channel을 증강시킬 필요가 있다. 예를 들어 구글 사의 최첨단 시스템은 blacklist를 사용하는데, 특정 토큰 (숫자, 구두점 및 한글자 단어)가 변경되는 것을 방지한다. 이러한 시스템 같은 경우 보다 후보자 보정을 신뢰하는 것에 대해 결정하는데 조심스럽다. 후보자 보정을 선택하는 것 대신에 만약 높은 확률이 그 단어보다 가지고 있다면 보다 조심스러운 시스템은 보정 w가 보정되지 않은 x를 지키는 데에 있어서 그 확률차가 확실히 더 커야만한다. 최고의 보정 w는 오직 다음과 같은 조건에서 선택된다:
$$log P(w|x) - log P(x|x) > \theta $$
특별한 작용에 의존하여, 스펠링 확인자는 autocorrect(자동으로 설정된 보정으로 스펠링을 고치는)를 결정하거나 단순히 오류를 표시하고 제안을 제공하면 된다. 이러한 결정은 최고의 후보자가 충분히 좋다고 선택될 때에만 classifier에 의해 결정되며, 이는 후보자들 사이의 log 확률의 차이같은 feature를 이용한다.
현대 시스템에서는 또한 초기 시스템보다 더 거대한 사전을 사용한다. Ahmad와 Kondrak은 100,000개의 UNIX dictionary가 오직 web query, missing된 단어인 pics, multiplayer, google과 같은 단어의 corpus에서 단어 type의 73%만을 포함하고 있다는 것을 밝현다. 이러한 이유에서 현대 시스템에서는 종종 Google N-gram corpus와 같은 unigram의 매우 거대한 list로부터 자동으로 유도된 거대한 사전들을 사용한다. 왜냐하면 그 목록은 많은 오탈자를 포함하고 있어서, 그들의 시스템은 보다 복잡한 에러 모델을 요구한다. 단어가 일반적으로 그들의 오탈자보다 빈번하다는 사실은 후보자 암시에 사용될 수 있으며, 그것은 단어의 세트를 만들고 유사한 문맥을 가지고 있는 스펠링 변화, 빈도수에 의한 정렬, 제공자로써의 가장 빈도수가 많은 변화를 다루는 것, 그리고 web text나 query log로부터의 차이를 학습하는 error model등이 있다. 단어들은 또한 유저가 보정을 거절하거나 핸드폰 상에서 작동하는 시스템이 자동으로 유저의 주소북이나 달력에 단어를 추가하는 것으로 사전에 데이터를 추가할 수 있다.
우리는 또한 prior와 likelihood가 결합하는 방법을 바꿔서 noisy channel model의 performance를 향상시킬 수 있다. 표준 모델에서 그것은 그저 곱해진다. 그러나 이러한 확률들은 상응하지 않는다; 그 언어 모델이나 채널 모델은 매우 다른 범위를 가지고 있다. 대안적으로 몇몇의 task가 dataset에서 우리는 두 개의 모델 중에 하나를 더 신뢰할 이유를 가지고 있다. 그러므로 우리는 combination에 weight를 주어 factor들중 하나에 더 신뢰성을 준다:
$$ \hat{w} = argmax_{w\in V} P(x|w) P(w)^{\lambda} $$
혹은,
$$ \hat{w} = argmax_{w\in V} logP(x|w) + \lambda log P(w) $$
와 같이 나타낼 수 있으며 파라미터 $\lambda$의 값은 development set으로 부터 tuning할 수 있다.
마지막으로, 우리의 목적이 만약 peace/piece, affect/effect, weather/whether 심지어 문맥 장의 보정 예시인 among/between까지 confusion set들을 위한 real-word 스펠링 보정에 있다면, 우리는 두 개의 후보자들 사이에 선택하기 위하여 문맥 상의 많은 feature들을 그려넣는 supervised classifier를 학습시킬 수 있다. 이러한 classifier는 이러한 특별한 set들에 한하여 매우 높은 정확도를 가지고 있으며, 특히 웹 통계로부터 온 large-scale feature에 톡톡히 효과를 보고있다.
Improved Edit Models: Partitions and Pronunciation
다른 최근 연구는 channel model P(t|c)를 향상시키는데 집중하고 있다. 하나의 중요한 확장은 복수의 문자열 transformation을 위한 확률을 계산하는 능력이다. 예를 들어 Brill and Moore는 입력자에 의해 생성된 error를 모델링하는 channel model을 제안하였는데, 먼저 단어를 선택하고, 그 단어의 문자열들의 partition을 선택한다, 그 후에 실수로 각 partition들을 입력하는 것이다. 예를 들어, 단어 physical을 생각하는 사람을 떠올리고, 이 단어의 partition을 ph y s i c al로 선택하자. 그녀는 각 partition을 가능한 에러와 함께 생성할 것이다. 예를 들어 그녀가 생성한 문자열 fisikle (partition은 f i s i k le)은 $p(f|ph) * p(i|y) * p(s|s) * p(i|i) * p(k|k) * p(le|al)$이 될 것이다. Damerau-Levenshtein edit distance와는 다르게 Brill-Moore channel model은 그러므로 P(f|ph)나 P(le|al) 혹은 P(ent|ant)와 같은 edit probability를 모델링할 수 있다. 더 나아가, 각각의 교정은 단어가 beginning, middle, end에 있냐에 따라 조건화되므로, P(f|ph)는 실질적으로 P(f|ph, beginning)과 매칭된다.
더 형식적으로, R을 오타 문자열 x를 인접한 (가능하면 빈) 하위 문자열로 분할하고, T는 후보자 문자열의 파티션이라고 하자. 그런 다음 Brill과 Moore는 total likelihood P(x|w)를 다음과 같이 근사하였다:
$$ P(x|w) \approx \max_{\text{R,T s.t. }|T|=|R|} \sum^{|R|}_{i=1}P(T_i|R_i,\text{position}) $$
각 변환 $P(T_i|R_i)$의 확률은 error triples의 training set으로부터 학습되고 그것이 반복적으로 일어난다. 예를 들어 training pair akgsual/actual이 주어졌을 때, 표준 minimum edit distance는 alignment을 생성하는데 사용한다:

이러한 alignment는 편집 operation의 서열을 따르게 된다:
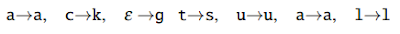 각각의 불일치 치환은 최대 N개의 추가 편집을 통합하도록 확장된다. N=2인 경우, $c \rightarrow k$를 다음과 같이 확장한다:
각각의 불일치 치환은 최대 N개의 추가 편집을 통합하도록 확장된다. N=2인 경우, $c \rightarrow k$를 다음과 같이 확장한다:
 이러한 다수의 편집들의 각각은 분수 count를 획득하고 그후에 각각의 edit $\alpha \rightarrow \beta$는 triple의 training corpus의 빈도수로부터 추측된다. $\frac{\text{count}(\alpha \rightarrow \beta)}{\text{count}(\alpha)}$.
이러한 다수의 편집들의 각각은 분수 count를 획득하고 그후에 각각의 edit $\alpha \rightarrow \beta$는 triple의 training corpus의 빈도수로부터 추측된다. $\frac{\text{count}(\alpha \rightarrow \beta)}{\text{count}(\alpha)}$.
Channel model의 또 다른 연구 방향으로는 단어의 스펠링과 더불어 발음을 이용하는 것이 있다. 단어의 metaphone 발음을 사용하는 GNU aspell 알고리즘과 같이 스펠링 보정을 위한 non-noisy channel algorithm에서 중요한 feature로 작용한다. Metaphone은 단어를 그 단어의 발음의 일반화된 표현법과 매칭시키는 규칙 중 하나이다. 이것의 몇 가지 예시의 규칙이다:
"C를 제외한 인접한 중복 문자를 제거한다"
"KN, GN, PN, AE, WR와 같은 묵음처리의 문자들에서 첫 번째 문자를 제거한다"
"M 이후나 단어의 끝에 있는 B는 제거한다"
aspell 알고리즘은 noisy channel model의 채널 구성 요소와 유사하게 작동하며, 오타로부터 short edit distance인 발음 문자열의 사전에서 모든 단어를 찾고 그 후 두 개의 edit distance를 결합한 행렬로부터 후보자들의 리스트를 점수화한다: pronunciation edit distance와 weighted letter edit distance.
발음 또한 noisy channel model에 직접적으로 통합될 수 있다. 직접적인 예시는 Toutanova와 Moore 모델인데, aspell과 같이, spelling에 기반된 모델과 발음에 기반한 모델, 즉 두 개의 channel model을 보간한다. 그 발음 모델은 단어의 발음을 뜻하는 phone의 서열로 각각의 input word와 각 사전의 단어들을 변환하는데, 이 때 letter-tosound 모델을 사용한다. 예시로, actress와 aktress는 서로 phone string인 ae k t r ix s에 매칭된다.
몇몇의 추가 string distance 함수들은 names를 특히 다루는 것으로 제안되었다. 이들은 보통 deduplication(census 목록이나 다른 namelist의 이름들이 서로 같은지 판단하는) 작업에 사용된다.
Soundex 알고리즘은 사람들의 이름을 표현하는 census 기록을 위한 오래된 방법이다. 이것은 옳게 스펠링된 이름들의 버전에 장점을 가지고 있다.
Soundex 알고리즘 대신에 가장 최근의 연구는 Jaro-Winkler distance를 이용하는 것으로 esit distance 알고리즘을 이용하여, 문자열이 보다 더 긴 이름에서 보다 긴 거리로 옮겨지도록 하고, 또한 이상적인 첫 문자를 가지는 문자열들로 보다 더 높은 유사성을 가지도록 하게 디자인한다.

이번 챕터에서는 스펠링 에러를 탐지하고 보정하는 문제에 대해 다루고자 한다. 스펠링 에러를 고치는 것은 현대 세계에서 쓰는 데에 있어서 중요한 부분인데, 쓰기 부분이라 함은 핸드폰을 통해 문자 메시지를 보내는 것일수도 있고 이메일을 보내는 것일 수도 있으며, 긴 문서를 작성하거나 웹 상에 정보를 찾아보는 것도 포함한다. 현대 스펠링 보정기는 완전하지는 않지만, 키보드의 인풋에 의존하는 소프트웨어들이라면 어디에나 있음직하다.
스펠링 보정은 두 가지의 전망으로부터 고려된다. 단어가 아닌 스펠링 보정은 결과적으로 단어가 아니게 되는 스펠링 에러를 탐지하고 보정하는 일이다. (예를 들어, 기런이라는 단어는 없지만 기린과 유사해보인다.) 이와 대조적으로 현실 세계 스펠링 보정은 그 스펠링 에러가 결과적으로 영어의 현재 단어를 나타내어도 그 에러를 탐지하고 보정하는 것이다. (real-word errors) 예를 들어, 인쇄상의 오류로 인해 이루어질 수 있는데, 실제 단어를 유연히 생성하는 there for three라던가 동음이의어(cognitive errors)로 인한 dessert for desert, piece for peace와 같은 단어들이 존재하겠다.
단어가 아닌 에러(Non-word Errors)는 사전으로부터 발견되지 않은 단어를 보는 것으로 탐지된다. 예를 들어 잘 못 스펠링된 graffe와 같은 경우에는 dictionary에 발견되지 않는다. 보다 거대한 dictionary가 더 좋다고 말할 수 있다. 현대 시스템에는 종종 web으로부터 유도된 거대한 사전을 사용하기도 한다. 단어가 아닌 에러를 보정하기 위해 첫 번째로 후보자들(candidates)들을 생성한다: 실제 단어는 에러와 유사한 문자 서열을 가지고 있다. 스펠링 에러로부터 후보자 보정에서 graffe같은 경우에는 giraffe, graf, gaffe, grail 혹은 craft와 같은 후보자들이 있다. 우리는 소스와 표면 에러 사이로부터 distance metric을 구하고 이를 사용하여 후보자들에게 순위를 매긴다. 우리는 graffe라는 non-word error에 대하여 giraffe가 보다 수정되어야 할 단어라고 추측하는데, giraffe가 grail보다 graffe라는 non-word error에 대해 유사한 폼을 가지고 있기 때문이다. 챕터 2의 minimum edit distance algorithm은 여기서 이를 위한 역할을 수행한다. 그러나 우리는 또한 보다 빈도수가 많은 단어나 error의 context에 보다 나옴직한 단어들로 보정하는 것도 선호하기도 한다. 다음 섹션의 noisy channel model은 이러한 추측을 형태화시키는 방법을 제공한다.
실제 단어 스펠링 에러(real word spelling error) 탐지는 더욱 더 어려운 작업이다. 아직, 유저에 의해 입력된 각 단어 w에 대해 후보자들을 찾는 noisy channel을 사용하거나 유저의 원래 의향대로 있음직한 보정을 순위를 매기는 것은 가능하긴 하다.
Noisy Channel Model
이번 섹션에서는 noisy channel model을 소개하고 이것을 스펠링 에러를 탐지하고 보정하는 데에 있어 어떻게 적용되는지 살펴보겠다. Noisy channel model은 AT&T Bell Laboratory와 IBM Watson Research의 연구자들이 동시간데에 스펠링 보정을 적용시킨 모델이다.

noisy channel model의 추측은 만약 옳게 스펠링된 단어가 noisy communication channel에 의해 왜곡되었을때, 잘못 스펠링된 단어를 다루는 것이다.
그 channel은 "진짜" 단어를 인지하기 어렵게 만드는 단어의 변형의 형태로 "noise"를 제공한다. 그러므로, 우리의 목표는 이러한 channel의 model을 만드는 것이다. 주어진 모델에 대해 우리는 noisy channel의 우리의 모델을 언어의 모든 단어를 통과시키는 것으로 진짜 단어를 찾고 잘못 스펠링된 단어와 가장 가까운 단어를 찾는 것이다.
그 noisy channel model은 Bayesian inference의 한 일종이다. 잘못 스펠링된 단어인 관찰 x를 보고, 우리의 작업은 이러한 잘못 스펠링된 단어를 생성시키는 단어 w를 찾는 것이다. 사전 V에서 P(w|x)가 가장 높게 나타나는 모든 가능한 단어 w들을 찾길 원한다. 우리는 hat notation ^을 옳은 단어 우리의 추측을 의미하는데 사용한다.
$$ \hat{w} = argmax_{w\in V} P(w|x) $$
함수 $argmax_{x}f(x)$는 $f(x)$값을 최대화 시키는 $x$를 의미한다. 위의 식은 그러므로 사전에서 나타나는 모든 단어들에서, 우리는 우변식 $P(w|x)$를 최대화시키는 특정 단어를 찾는다는 것이다.
Bayesian Classification의 추측은 다른 확률의 set으로 Bayes' rule을 이용하여 식을 변형시키는 것이다. Bayes' rule은 아래의 식에 설명되어 있다. 그것은 하나의 조건부 확률 $P(a|b)$를 다른 세가지의 확률로 분해하는 방법을 제공한다:
$$P(a|b) = \frac{P(b|a) P(a)}{P(b)}$$
우리는 두 가지의 식을 합쳐 다음과 같은 식을 유도할 수 있다:
$$\hat{w} = argmax_{w\in V} \frac{P(x|w)P(w)}{P(x)} $$
우리는 편리하게 이 식에서 denominator P(x)를 제거하는 것으로 간단화시킬 수 있다. 이것이 가능한 이유는 모든 단어에서 가능성있는 보정 단어를 선택할 때 우리는 각 단어의 $\frac{P(x|w)P(w)}{P(x)}$를 계산한다. 하지만 P(x)는 각 단어들에서 변하지 않는다. 우리는 항상 관찰된 에러 x에 대해 있음직한 단어를 알아보기 때문에 P(x)에 대해 같은 확률을 가진다. 그러므로 우리는 보다 더 간단해진 형태를 최대화 시키는 단어를 선택하면 된다:
$$\hat{w} = argmax_{w\in V} P(x|w)P(w) $$
요약하면, noisy channel model은 우리가 진정한 기본 단어 w를 가지고 있다고 말하며, 우리는 가능성있는 잘못 스펠링됭 표면형으로 단어를 수정시키는 noisy channel을 가지고 있다는 것이다. 그 특정 관찰 서열 x를 생성하는 noisy channel의 likelihood 혹은 channel model은 P(x|w)에 의해 모델링된다. 이 때 prior P(w)와 likelihood P(x|w)를 곱하고 그 곱이 가장큰 단어를 선택하는 것으로 관찰된 잘못 스펠링된 x를 보는 것으로 hidden word의 prior probability는 P(w)에 의해 모델링된다. 우리는 가장 유망한 후보자 단어 $\hat{w}$를 계산한다.
우리는 우리의 스펠링 사전에서 나타나지 않는 단어를 찾고 후보자 단어의 리스트를 작성하고, 그것들에 순위를 매기고 가장 순위가 높은 단어를 선택하는 것으로 단어가 아닌 스펠링 에러를 보정하는 것으로 noisy channel 접근 방법을 사용한다. 우리는 식을 전체 사전 V 대신에 후보자 리스트들을 참조함으로 수정할 수 있다.
$$ \hat{w} = argmax_{w\in C} P(x|w)P(w) $$
이 때 P(x|w)는 channel model이고 P(w)는 prior이다. likelihood와 prior를 계산하기 위한 detail을 보기위해 예시를 살펴보자.

알고리즘의 첫번째 단계는 단어를 찾는 것으로 input word와 유사한 spelling을 가진 단어 후보자들을 보는 것이다. 스펠링 에러 데이터의 분석은 각 문자를 구성하는 spelling error를 보고 그러므로 우리는 error word로부터 후보자들이 1의 edit distance만 갖는다고 간단한 추측을 할 수 있다. 우리는 Chapter 2에서 소개된 minimum edit distance algorithm을 사용할 것이지만 후보자 리스트를 찾기 위해 insertion deletion 그리고 substitution에 대해 확장된 버전인 transposition이라는 한 가지 형태를 더 추가한다. transposition 형태가 추가된 edit distance version은 Damerau-Levenshtein edit distance라 불린다.

각 보정값 P(w)의 prior 확률은 context에서 단어 w가 나타나는 언어 모델 확률인데, 이는 unigram부터 trigram 혹은 4-gram으로부터 어떠한 언어 모델을 사용하여 계산될 수 있다. 예시를 통해 unigram 언어 모델을 시작해보자. 우리는 Corpus of Contemporary English (COCA)의 단어 404,253,213개로부터 언어 모델을 계산하였다.
예를 들어 간단한 모델은 추측한다, p(acress|across)가 그저 에러의 거대한 corpus에서 letter o가 letter e로 치환된 빈도수를 세는 것이라고. 이러한 방법을 통해 확률을 계산하기 위해서는 우리는 error의 빈도수를 세는 confusion matrix를 요구한다. 일반적으로, confusion matrix는 또 다른 단어와 혼동하였을 때의 빈도수를 나열한다. 그러므로 예를 들어 substitution matrix는 26*26 사이즈의 정사각행렬로 묘사되는데, 이는 하나의 문자가 또 다른 문자로 옳지 않게 사용된 빈도수를 체크한다. 우리는 4개의 confusion matrix를 사용할 것이다.
del[x,y]: count(xy typed as x)
ins[x,y]: count(x typed as xy)
sub[x,y]: count(x typed as y)
trans[x,y]: count(x typed as yx)
다음의 것들을 이러한 것의 한 예시이다:
additional: addional, additonal
environments: enviornments, enviorments, enviroments
preceded: preceeded
...
이러한 list는 Wikipedia와 Roger Mitton 그리고 Peter Norvig에서 이용가능하다. Norvig는 또한 각각의 싱글 문자열의 빈도수를 제공하는데, 이는 바로 에러 모델 확률을 만들 수 있다.
Kernighan et al.에 의해 제안된 접근 방법은 이 스펠링 에러 보정 알고리즘을 반복적으로 그것의 행렬값을 계산하는 것이다. 이 반복적인 알고리즘은 처음에는 같은 값으로 행렬을 시작하는데, 이는 어느 문자든 동일하게 삭제될 수 있으며, 동일하게 다른 문자와 치환될 수 있음을 뜻한다. 다음은 스펠링 에러 보정 알고리즘은 스펠링 에러의 세트에서만 작동한다. 그들의 예측된 보정과 함께 페어링된 오타들의 주어진 세트에서 confusion 행렬은 다시 재계산되고, 스펠링 알고리즘은 다시 작동하는 방식이다. 이러한 반복 알고리즘은 중요한 EM 알고리즘의 표본이다.
우리가 confusion matrix를 가지고 있을때 우리는 다음과 같이 P(x|w)를 예측하고 ($w_i$는 올바른 단어 w의 i-th 문자열이다) 그리고 $x_i$는 오타 x의 i-th 문자열이다.
$$P(x|w) = \begin{cases} \frac{\text{del}[x_{i-1}, w_i]}{\text{count}[x_{i-1}w_i]}, & \text{if deletion} \\ \frac{\text{ins}[x_{i-1}, w_i]}{\text{count}[w_{i-1}]}, & \text{if insertion} \\ \frac{\text{sub}[x_i, w_i]}{\text{count}[w_i]}, & \text{if substitution} \\ \frac{\text{trans}[w_i, w_{i+1}]}{\text{count}[w_iw_{i+1}]}, & \text{if transposition} \end{cases} $$
Kernighan et al.를 참조한 빈도수를 사용한 결과는 다음과 같다.

아래의 그림은 각 가능성있는 보정형태의 최종 확률을 보여준다; unigram prior는 likelihood에 의해 곱해진다. 마지막 column은 가독성을 위해 10의 9승을 곱하였다.

Figure 5.5의 계산은 noisy channel 모델의 우리의 implementation이 최고의 보정으로 across를 선택한다는 것이고, 두 번째로는 actress를 선정한다는 것이다.
공교롭게도 여기의 알고리즘은 옳지 못하다. 왜냐하면 작가의 의도가 맥락에서 명확히 전달되는 경우가 있기 때문이다: ... was called a "stellar and versatile acress whose combination of sass and glamour has defined her... ". 주위의 단어들은 actress가 across보다 명확한 단어임을 말해준다.
이러한 이유로, unigram보다 거대한 언어 모델을 사용하는 것이 중요하다. 예를 들어 만약 우리가 Corpus of Contemporary American English를 단어 actress와 across에서 add-one smoothing을 사용해 bigram 확률을 계산한다면, 우리는 다음과 같은 확률을 얻을 수 있다:
P(actress|versatile) = .000021
P(across|versatile) = .000021
P(whose|actress) = .0010
P(whose|across) = .000006
그렇다면 이 식을 곱하면 다음과 같은 식을 얻을 수 있다.
P("versatile actress whose") = .000021 * .0010 = 210 * 10^(-10)
P("versatile across whose") = .000021 * .000006 = 1 * 10^(-10)
Figure 5.5의 error model과 함께 언어 모델을 결합하여 bigram noisy channel model은 현재 올바르게 보정된 단어인 actress를 선택한다.
Real-word spelling errors
그 noisy channel 접근 방법은 또한 real-word spelling error를 탐지하고 수정하는데 적용될 수 있는데, 이는 영어의 실제 단어들에서 나타나는 에러를 뜻한다. 이것은 인쇄상의 에러로부터 일어날 수 있으며 (insertion, deletion, transposition) 우연치않게 실제 단어를 생성하거나 글쓴이가 동음이의어나 동음이의어에 가까운 것들을 잘못 스펠링하였을 때 나타나는 현상이다.
noisy channel은 또한 real-word 에러를 다룰 수 있다. 이 real-word spelling error를 다루기 위한 Mays et al의 처음 제안한 noisy channel model을 살펴보자. 그들의 알고리즘은 input sentence $X = {x_1, x_2, ..., x_k, ..., x_n}$를 사용하여 후보자 보정 문장 C(x)의 거대한 세트를 생성하고 가장 최고로 높은 언어 모델 확률의 문장을 선택한다.
후보자 보정 문장을 생성하기 위해 우리는 각 input word인 $x_i$에 대하여 후보자 단어를 생성하는 것으로 시작한다. 후보자 $C(x_i)$는 $x_i$로부터의 작은 edit distance와 함께 모든 영어 단어를 포함한다. edit distance 1은, thew라는 real word에 대해 다음과 같은 후보군이 생성된다. C(thew) = {the, thaw, threw, them, thwe}. 우리는 그 후에 오직 하나의 에러만을 갖는 모든 문장을 갖는 다는 간단한 추측을 한다. 그 후에 후보 문장 C(X)에 대하여 문장 X = Only two of thew apples는 다음과 같다:
only two of thew apples
oily two of thew apples
only too of thew apples
only to of thew apples
only tao of the apples
only two on thew apples
only two off thew apples
only two of the apples
only two of threw apples
only two of thew applies
only two of thew dapples
...
각각의 문장들은 noisy channel에 의해 scoring된다:
$$\hat{W} = argmax_{W\in C(X)} P(X|W) P(W) $$
P(w)를 위해 우리는 문장의 trigram 확률을 사용할 수 있다.
channel model은 어떠한가? 이러한 real word에 의하여 우리는 input word가 error가 아닐 확률을 고려해야만 한다. 단어를 작성하는 것의 channel 확률인 P(w|w)를 $\alpha$로 생각하자.
$$p(x|w) = \begin{cases} \alpha & \text{if } x = w \\ \frac{1-\alpha}{|C(x)|} & \text{if } x \in C(x) \\ 0 & \text{otherwise} \end{cases} $$
이제 우리는 모든 보정에 대한 $1-\alpha$의 같은 분포를 대체할 수 있다. 우리는 confusion matrix를 사용하는 Eq. 5.6으로부터 보다 복잡한 channel model인 edit probability에 비례하는 분포를 만들 것이다.
실제 단어에 적용된 이 통합된 noisy channel noisy의 예시를 바라보자. 우리가 문자열인 two of thew를 본다고 생각하자. 작성자는 아마 실제 단어 thew를 입력하기로 예정했다고 하자. 하지만 thew는 여기서 또한 the나 다른 단어로 오타가 날 수 있다. 이러한 예시의 목적을 위해 edit distance 1인 것들을 고려하고, 다섯 개의 후보군 the, thaw, threw 그리고 thwe와 입력된 thew를 고려해보자. 우리가 이 예시에서 Norvig의 edit 확률을 사용할 것이다. 언어 모델 확률을 위해 우리는 Stupid Backoff model을 사용하였다:
여기서 우리는 그저 기본형태의 구인 two of thew의 확률을 구하였지만, 모델은 전체 문장에 대해 적용한다. 그래서 만약 문맥에서의 예시가 two of thew people 이였다면, 우리는 또한 P(people|of the)나 P(people|of thew), P(people|of threw)와 같은 확률을 곱해주어야만 한다.

Noisy Channel Model: The State of The Art
noisy channel spelling correction의 최첨단 구현은 우리가 위에서 제공했던 간단한 모델의 확장 버전이다.
첫 번째로, 입력 문장이 오직 single error만 가지고 있다는 추측을 만드는 것보다 현재 시스템에서는 제 때에 입력 하나의 단어를 통해 살펴보고 그 단어에 대해 noisy channel을 이용하여 결정권을 내린다. 그러나 우리가 각 단어에 대하여 묘사된 기본 noisy channel system을 작동하기 위해서는 그것은 정확하지만 희귀한 단어를 보다 빈번한 단어로 대체하여 과보정(overcorrecting)하는 경우가 많다. 현대 알고리즘은 그러므로 실제 단어가 실제로 옳은지 아닌지를 판단하는 방법들과 함께 noisy channel을 증강시킬 필요가 있다. 예를 들어 구글 사의 최첨단 시스템은 blacklist를 사용하는데, 특정 토큰 (숫자, 구두점 및 한글자 단어)가 변경되는 것을 방지한다. 이러한 시스템 같은 경우 보다 후보자 보정을 신뢰하는 것에 대해 결정하는데 조심스럽다. 후보자 보정을 선택하는 것 대신에 만약 높은 확률이 그 단어보다 가지고 있다면 보다 조심스러운 시스템은 보정 w가 보정되지 않은 x를 지키는 데에 있어서 그 확률차가 확실히 더 커야만한다. 최고의 보정 w는 오직 다음과 같은 조건에서 선택된다:
$$log P(w|x) - log P(x|x) > \theta $$
특별한 작용에 의존하여, 스펠링 확인자는 autocorrect(자동으로 설정된 보정으로 스펠링을 고치는)를 결정하거나 단순히 오류를 표시하고 제안을 제공하면 된다. 이러한 결정은 최고의 후보자가 충분히 좋다고 선택될 때에만 classifier에 의해 결정되며, 이는 후보자들 사이의 log 확률의 차이같은 feature를 이용한다.
현대 시스템에서는 또한 초기 시스템보다 더 거대한 사전을 사용한다. Ahmad와 Kondrak은 100,000개의 UNIX dictionary가 오직 web query, missing된 단어인 pics, multiplayer, google과 같은 단어의 corpus에서 단어 type의 73%만을 포함하고 있다는 것을 밝현다. 이러한 이유에서 현대 시스템에서는 종종 Google N-gram corpus와 같은 unigram의 매우 거대한 list로부터 자동으로 유도된 거대한 사전들을 사용한다. 왜냐하면 그 목록은 많은 오탈자를 포함하고 있어서, 그들의 시스템은 보다 복잡한 에러 모델을 요구한다. 단어가 일반적으로 그들의 오탈자보다 빈번하다는 사실은 후보자 암시에 사용될 수 있으며, 그것은 단어의 세트를 만들고 유사한 문맥을 가지고 있는 스펠링 변화, 빈도수에 의한 정렬, 제공자로써의 가장 빈도수가 많은 변화를 다루는 것, 그리고 web text나 query log로부터의 차이를 학습하는 error model등이 있다. 단어들은 또한 유저가 보정을 거절하거나 핸드폰 상에서 작동하는 시스템이 자동으로 유저의 주소북이나 달력에 단어를 추가하는 것으로 사전에 데이터를 추가할 수 있다.
우리는 또한 prior와 likelihood가 결합하는 방법을 바꿔서 noisy channel model의 performance를 향상시킬 수 있다. 표준 모델에서 그것은 그저 곱해진다. 그러나 이러한 확률들은 상응하지 않는다; 그 언어 모델이나 채널 모델은 매우 다른 범위를 가지고 있다. 대안적으로 몇몇의 task가 dataset에서 우리는 두 개의 모델 중에 하나를 더 신뢰할 이유를 가지고 있다. 그러므로 우리는 combination에 weight를 주어 factor들중 하나에 더 신뢰성을 준다:
$$ \hat{w} = argmax_{w\in V} P(x|w) P(w)^{\lambda} $$
혹은,
$$ \hat{w} = argmax_{w\in V} logP(x|w) + \lambda log P(w) $$
와 같이 나타낼 수 있으며 파라미터 $\lambda$의 값은 development set으로 부터 tuning할 수 있다.
마지막으로, 우리의 목적이 만약 peace/piece, affect/effect, weather/whether 심지어 문맥 장의 보정 예시인 among/between까지 confusion set들을 위한 real-word 스펠링 보정에 있다면, 우리는 두 개의 후보자들 사이에 선택하기 위하여 문맥 상의 많은 feature들을 그려넣는 supervised classifier를 학습시킬 수 있다. 이러한 classifier는 이러한 특별한 set들에 한하여 매우 높은 정확도를 가지고 있으며, 특히 웹 통계로부터 온 large-scale feature에 톡톡히 효과를 보고있다.
Improved Edit Models: Partitions and Pronunciation
다른 최근 연구는 channel model P(t|c)를 향상시키는데 집중하고 있다. 하나의 중요한 확장은 복수의 문자열 transformation을 위한 확률을 계산하는 능력이다. 예를 들어 Brill and Moore는 입력자에 의해 생성된 error를 모델링하는 channel model을 제안하였는데, 먼저 단어를 선택하고, 그 단어의 문자열들의 partition을 선택한다, 그 후에 실수로 각 partition들을 입력하는 것이다. 예를 들어, 단어 physical을 생각하는 사람을 떠올리고, 이 단어의 partition을 ph y s i c al로 선택하자. 그녀는 각 partition을 가능한 에러와 함께 생성할 것이다. 예를 들어 그녀가 생성한 문자열 fisikle (partition은 f i s i k le)은 $p(f|ph) * p(i|y) * p(s|s) * p(i|i) * p(k|k) * p(le|al)$이 될 것이다. Damerau-Levenshtein edit distance와는 다르게 Brill-Moore channel model은 그러므로 P(f|ph)나 P(le|al) 혹은 P(ent|ant)와 같은 edit probability를 모델링할 수 있다. 더 나아가, 각각의 교정은 단어가 beginning, middle, end에 있냐에 따라 조건화되므로, P(f|ph)는 실질적으로 P(f|ph, beginning)과 매칭된다.
더 형식적으로, R을 오타 문자열 x를 인접한 (가능하면 빈) 하위 문자열로 분할하고, T는 후보자 문자열의 파티션이라고 하자. 그런 다음 Brill과 Moore는 total likelihood P(x|w)를 다음과 같이 근사하였다:
$$ P(x|w) \approx \max_{\text{R,T s.t. }|T|=|R|} \sum^{|R|}_{i=1}P(T_i|R_i,\text{position}) $$
각 변환 $P(T_i|R_i)$의 확률은 error triples의 training set으로부터 학습되고 그것이 반복적으로 일어난다. 예를 들어 training pair akgsual/actual이 주어졌을 때, 표준 minimum edit distance는 alignment을 생성하는데 사용한다:
이러한 alignment는 편집 operation의 서열을 따르게 된다:
Channel model의 또 다른 연구 방향으로는 단어의 스펠링과 더불어 발음을 이용하는 것이 있다. 단어의 metaphone 발음을 사용하는 GNU aspell 알고리즘과 같이 스펠링 보정을 위한 non-noisy channel algorithm에서 중요한 feature로 작용한다. Metaphone은 단어를 그 단어의 발음의 일반화된 표현법과 매칭시키는 규칙 중 하나이다. 이것의 몇 가지 예시의 규칙이다:
"C를 제외한 인접한 중복 문자를 제거한다"
"KN, GN, PN, AE, WR와 같은 묵음처리의 문자들에서 첫 번째 문자를 제거한다"
"M 이후나 단어의 끝에 있는 B는 제거한다"
aspell 알고리즘은 noisy channel model의 채널 구성 요소와 유사하게 작동하며, 오타로부터 short edit distance인 발음 문자열의 사전에서 모든 단어를 찾고 그 후 두 개의 edit distance를 결합한 행렬로부터 후보자들의 리스트를 점수화한다: pronunciation edit distance와 weighted letter edit distance.
발음 또한 noisy channel model에 직접적으로 통합될 수 있다. 직접적인 예시는 Toutanova와 Moore 모델인데, aspell과 같이, spelling에 기반된 모델과 발음에 기반한 모델, 즉 두 개의 channel model을 보간한다. 그 발음 모델은 단어의 발음을 뜻하는 phone의 서열로 각각의 input word와 각 사전의 단어들을 변환하는데, 이 때 letter-tosound 모델을 사용한다. 예시로, actress와 aktress는 서로 phone string인 ae k t r ix s에 매칭된다.
몇몇의 추가 string distance 함수들은 names를 특히 다루는 것으로 제안되었다. 이들은 보통 deduplication(census 목록이나 다른 namelist의 이름들이 서로 같은지 판단하는) 작업에 사용된다.
Soundex 알고리즘은 사람들의 이름을 표현하는 census 기록을 위한 오래된 방법이다. 이것은 옳게 스펠링된 이름들의 버전에 장점을 가지고 있다.
Soundex 알고리즘 대신에 가장 최근의 연구는 Jaro-Winkler distance를 이용하는 것으로 esit distance 알고리즘을 이용하여, 문자열이 보다 더 긴 이름에서 보다 긴 거리로 옮겨지도록 하고, 또한 이상적인 첫 문자를 가지는 문자열들로 보다 더 높은 유사성을 가지도록 하게 디자인한다.


댓글
댓글 쓰기