SWRC) Stating the Obvious: Extracting Visual Common Sense Knowledge 번역, 정리
Stating the Obvious: Extracting Visual Common Sense Knowledge
명백한 진술: 시각적인 상식 추출
*시각적 데이터를 토대로 상식을 추출한다는 것이 더 맞는 표현인것 같다.
*논문 요약은 맨 마지막에 있다.
*논문 요약은 맨 마지막에 있다.
Abstract
Obtaining common sense knowledge using current information extraction techniques is extremely challenging. In this work, we instead propose to derive simple common sense statements from fully annotated object detection corpora such as the Microsoft Common Objects in Context dataset. We show that many thousands of common sense facts can be extracted from such corpora at high quality. Furthermore, using WordNet and a novel submodular k-coverage formulation, we are able to generalize our initial set of common sense assertions to unseen objects and uncover over 400k potentially useful facts.
현재 정보 추출 기술을 사용하여 상식을 얻는 것은 매우 도전적인 일이다. 이번 작업에서, 우리는 Context dataset에서 Microsoft Common Objects와 같은 전체적으로 annotate된 object 검출체로부터 간단한 상식을 파생하는 것을 제안하려 한다. 우리는 상식의 몇 천가지 사실들이 높은 quality로 이러한 corpora로부터 추출될 수 있다는 것을 보여준다. 더 나아가 WordNet과 novel submodular k-coverage formulation을 사용하여, 우리는 보이지 않은 것들에 대한 초기 상식 주장을 일반화하고 40만 가지가 넘는 유용한 사실들을 밝힐 수 있다.
Introduction
How can we discover that bowls can hold broccoli, that if a knife touches a cake then a person is probably cutting cake, or that cutlery can be on dining tables? We propose to leverage the effort of computer vision researchers in creating large scale datasets for object detection and use these resources instead to extract symbolic representations of visual common sense. The knowledge we compile is physical, not commonly covered in text and more exhaustive than what people can usually produce.
우리는 어떻게 그릇에 브로콜리가 담겨있다는 것을 알고, 칼이 케이크에 닿으면 사람이 아마 케이크를 자르고 있다는 것이나 칼 붙이가 식탁에 놓일 수 있다는 것을 알 수 있나? 우리는 객체 탐지를 위한 거대한 스케일의 dataset을 생성하는 컴퓨터 비전 연구원들의 노력을 활용하고 이러한 자원들을 시각적 상식의 상징적 표현을 추출하기 위해 사용하도록 제안한다. 우리가 컴파일한 상식은 물리적이며, 흔히 text로 배우는 것이 아니며, 사람들이 보통 생성할 수 있는 것보다 더 철저하다.
Our focus is particularly on visual common sense, defined as the information about spatial and functional properties of entities in the world. We propose to extract three types of knowledge from the Microsoft Common Objects in Context dataset, consisting of 300,000 images, covering 80 objects, with object segments and natural language captions. First, we find spatial relations, e.g. holds(bed, dog), from outlines of co-occurring objects. Next, we construct entailment rules like holds(bed, dog) => laying-on(dog, bed) by associating spatial relations with text in captions. Finally, we uncover general facts such as holds(furniture, domestic animal), applicable to object types not present in MS-COCO by using WordNet and a novel submodular k-coverage formulation.
우리의 목적은 특별히 시각적 상식에 있으며, 이는 세계 entity들의 공간적 및 기능적 특성에 대한 정보로 정의된다. 우리는 30만개의 이미지, 80개의 object, object segment, 그리고 자연어 caption을 포함한 Context dataset의 Microsoft Common Objects로부터 세 가지의 지식을 추출하도록 제안한다. 첫 번째는, 공간적 관계를 찾아냅니다. 예로, holds(bed, dog)와 같은 관계로 의미있는 물체들의 윤곽을 통해 밝혀낸다. 그 후 우리는 귀결 규칙을 만들어 낸다. 예시로, holds(bed, dog)는 laying-on(dog,bed)와 같은 사실로 도약할 수 있는데, 이는 caption에 있는 text를 통해 공간적 관계를 도출하는 것으로 이루어진다. 마지막으로, 우리는 WordNet과 novel submodular k-coverage formulation을 사용하여 MS-COCO에는 제공되지 않는 객체 유형에 적용시킬 수 있는 holds(furniture, domestic animal)과 같은 일반적 사실들을 밝힌다.
* 이를 정리해보면 caption text, image, object, object segment등의 dataset을 통해 시각적 상식을 추출한다. 여기서 말하는 시각적 상식이란, dataset이 image이므로 image로부터 추출해낸 상식이다보니, visual common sense라 언급하는 것 같다. 이 때 총 3단계를 거쳐 상식을 추출하는데, 하나는 이미지의 윤곽을 통해서 무엇이 무엇과 있는지와 같은 관계를 알아내고, 두 번째로는 해당 이미지에서 나온 상식과 caption text를 비교하여 귀결 규칙을 만들고, 마지막으로는 이를 통해 일반적인 상식을 만들어내는 것이다.
Evalutaions using crowdsourcing show our methods can discover many thousands of high quality explicit statements of visual common sense. While some of this knowledge can be potentially extracted from text, we found that from our top 100 extracted spatial relational, e.g. holds(bed, dog), only 4 are present in some form in the AtLocation relations in the popular ConceptNet knowledge base. This shows that the knowledge we derive provides complimentary information for other more general knowledge bases.
Such common sense facts have proved useful for query expansion and could benefit entailment, grounded entailment, or visual recognition tasks.
크라우드소싱을 사용한 평가방법은 우리의 방법이 시각적 상식의 높은 수준의 상태들의 몇 천 가지들을 밝혀낼 수 있다는 것을 보여준다.
*크라우드소싱은 기업활동의 전 과정에 소비자나 대중이 참여할 수 있도록 일부를 개방하고, 참여자의 기여로 기업활동 능력이 향상되며 그 수익을 참여자와 공유하는 기법.
이러한 지식 일부분이 잠재적으로 text로부터 추출될 수 있는 반면에, 우리는 100개의 추출 공간 관계로부터 이를 찾아냈고, 오직 4개만이 인기있는 ConceptNet 상식 base에서 AtLocation 관계에 있는 몇 가지의 형태로 존재했다. 이것은 우리가 파생한 지식이 다른 보다 일반적인 지식 기반에 대한 무료 지식을 제공하는 것을 보여준다.
* text로 추출된 방식의 상식들은 저자가 추출한 관계에서 발견됐으므로, 저자의 방식이 좀 더 일반화된 상식을 추출할 수 있다고 설명하고 있음.
이러한 일반적 상식들은 query 확장에 유용하다고 증명됐으며, 귀결, grounded 귀결 규칙, 시각 인지 활동에 이점을 준다.
Related Work
Common sense knowledge has been predominately created directly from human input or extracted from text. In contrast, our work is focused on visual common sense extracted from images annotated with regions and descriptions.
일반적 상식은 주로 인간의 입력이나 텍스트에서 추출되어 직접 만들어졌다. 이와 대조적으로, 우리는 부분적으로 annotate되고 묘사와 함께 있는 image로부터 시각적 상식 추출에 초점이 있다.

There has also been recent interest in the vision community to build databases of visual common sense knowledge. Efforts have focused on a small set of relations, such as similar to or part of. Webly supervised techniques have also been used to test whether a particular object-relation-object triplet occurs in images. In contrast, we use seven spatial relations and allow natural language relations that represent a larger array of higher level semantics. We also leverage existing efforts on annotating large scale image datasets instead of relying on the noisy outputs of a computer vision system.
시각적 상식 지식의 database를 만들기 위한 vision community에 최근 관심이 급증했다. similar to나 part of와 같은 관계의 작은 set에 노력들이 집중되었다. Webly supervised 기술을 image 상에서 특이적인 object-relation-object 트리프이 나타나는지에 대해 test를 하는 데 사용되었다. 이와 대조적으로, 우리는 7가지 공간 관계를 사용하고, 더 높은 레벨 semantic의 더 거대한 행렬을 표현하는 자연어 관계를 허용한다. 우리는 또한 computer vision system의 노이즈가 있는 output에 의존하는 대신 대규모 이미지 dataset에 annotating을 하는 많은 노력을 활용했다.'
On a technical level, our methods for extracting common sense facts from images rely on Pointwise-Mutual Information, analogous to other rule extraction systems based on text. We view objects as an analogy for words, images as documents, and object-object configurations as typed bigrams. Our methods for generalizing relations are inspired by work that tries to predict a class label for an image given a hierarchy of concepts. Yet our work is the first to deal with visual relations between pairs of concepts in the hierarchy by using a sub-modular formulation that maximizes the amount of coverage of subordinate categories while avoiding contradictions with an initial set of discovered common-sense assertions.
기술적인 단계에서, 상식 사실들을 이미지로부터 추출하기 위한 우리의 방법은 text를 기반으로한 다른 규칙 추출 시스템에 유사한 Pointwise-Mutual 정보에 의존한다. 우리는 객체를 단어, 이미지를 문서로, 객체-객체 구성을 형식화된 bigram으로 유추한다. 관계들을 일반화시키는 우리의 방법은 concept hierarchy가 주어진 이미지의 class label를 예측하려는 작업에 영감을 얻었다. 그러나 우리의 연구는 하위 범주의 범위를 최대화하는 하위 모듈 형식을 사용하여 계층 구조의 개념 쌍 간에 시각적 관계를 처음으로 다루는데, 이와 동시에 발견된 상식 주장의 초기 set에 있는 모순들을 피한다.
Methods
We assume the availability of an object-level annotated image dataset D containing a set of images with textual descriptions. Each object in an image must be annotated with: (1) a mask or polygon outlining the extents of the object, and (2) the category of the object from a set of categories V and (3) an overall description of the image.
우리는 텍스트적 묘사가 있는 image set을 포함하는 객체 레벨의 annotate된 image dataset D가 있다고 가정한다. 하나의 image에 나타나는 각각의 객체들은 다음과 같은 조건과 함께 annotate되어야 한다: (1) object 범위를 표시한 mask나 polygon, (2) category V의 set으로부터 object의 category, 그리고 (3) image의 전체적인 description
* 즉 image set에서 필요한 것은, 각각의 객체를 mask하거나 polygon으로 표시한 data, 그리고 object의 category가 무엇인지 (ex) dog->domestic animal, 마지막으로 image의 전체적인 description으로 natural language caption을 의미한다.
We produce three types of common sense facts, each with an associated scoring function: (1) object-object relationships implicitly encoded in the relative configurations between objects in the annotated image data, i.e. on(bed, dog), (2) Entailment relations encoded in the relationships between object-object configurations and textual descriptions i.e. on(bed, dog) => laying-on(bed, dog), and (3) Generalized relations induced by using semantic hierarchy of concepts in Word-Net, i.e. on(furniture, domestic-animal).
우리는 세 가지 형태의 상식을 추출하는 데, 각각은 scoring function을 갖고 있다: (1) annotate된 image data의 object간 상대적인 구성에서 암시적으로 인코딩된 객체-객체 관계 (ex) on(bed, dog), (2) 객체-객체 구성과 텍스트 묘사 사이의 관계로 인코딩된 귀결 관계 (ex) on(bed, dog) => laying-on(bed, dog), 그리고 (3) Word-Net에서 의미적 계층 구조를 사용하여 유도된 일반화된 관계 (ex) on(furniture, domestic-animal).
Mining Object-Object Relations
Our objective in this sections is to score and rank a set of relations $S_1 = {r(o_1,o_2)}$, where $r$ is a object-object relation and $o_1, o_2\in V$ , using a function $\gamma_1 : S_1 \rightarrow R$. First, we define a vocabulary $R$ of object-object relations between pairs of annotated objects. Our relations are inspired by Region Connection Calculus, and the Visual Dependency Grammar of, details in Figure 1.
이 Section에서 우리의 목적은 relation $S_1$에 대해 점수와 랭킹을 매긴다. 이 때 $r$은 객체-객체간 관계이고, $o_1, o_2$는 Object group $V$에 포함되어 있으며, function $\gamma_1\ : S_1 \rightarrow R$를 사용한다. 먼저, 우리는 annotate된 object 쌍 사이에 object-object relation의 vocabulary $R$을 정의한다. 우리의 관계는 Figure 1에서 나타나는 디테일의 Visual Dependency Grammar와 Region Connection Calculus를 참조하였다.
For every image, we record the instances of each of these object-object relations $r(o_1,o_2)$ between all co-occurring object in $D^1$. We use Point-wise Mutual Information (PMI) to estimate the evidence for each relationship triplet:
$$\gamma_1(r(o_1,o_2)) = \log\frac{p[r(o_1,o_2)]}{p[r]p[(o_1,o_2)]}$$
모든 image 상에서, 우리는 $D^1$에 있는 모든 동시에 나타나는 object 사이에 object-object relation $r(o_1,o_2)$의 각각의 instance를 기록한다. 우리는 Point-wise Mutual Information을 사용해 각각의 관계 트리플의 증거를 추측한다:
$$\gamma_1(r(o_1,o_2)) = \log\frac{p[r(o_1,o_2)]}{p[r]p[(o_1,o_2)]}$$
* <noun, verb>, <noun,*,verb,*,noun>, <noun,*,preposition,*,noun>, <noun,*,verb,preposition,*,noun>
* z의 형태는 <noun, verb>, <noun,*,verb,*,noun>, <noun,*,preposition,*,noun>, <noun,*,verb,preposition,*,noun>이고, 이를 co-occuring relation $r(o_1,o_2)$와 비교하여 해당 object들이 포함되어있는지 파악하고, z와 r이 같이 data set에서 존재하는가에 따라 점수를 부여한다.

Generalizing Relations using WordNet
In this section we present an approach to generalize an initial set of relations, $S$, to objects not found in the original vocabulary $V$. Using WordNet we construct a superset $G$ containing all possible parent relations for the relations in $S$ by replacing their arguments $o_1,o_2$ by all their possible hypernyms. Our objective is to select a subset $T$ from $G$ that contains high quality and diverse generalized relations. Note that elements in $G$ can be too general and contradict statements in $S$ while others could be correct but add little new knowledge. To balance these concerns, we formulate the selection as an optimization problem by maximizing a fitness function $\mathcal{L}$:
$\max_T \mathcal{L}(T)$, such that $|T| = k$, and $T \subseteq G$,
$\mathcal{L}(T) = \lambda\log(1+\psi(T)) + \Sigma_{t\in T}log(1+\phi(t,S))$,
where $\psi$ is a coverage term that computes the total number of facts implied through hyponym relationships by the elements in $T$. The second term $\phi$ is a consistency term measures the compatibility of a generalized relation t with the relations in $S$. We assume that if a relation is missing from $S$, then it is false (this corresponds to a closed world assumption over the domain of $S$). Thus, $\phi$ is the ratio of the scores of relations in $S$ consistent with relation $t$ (i.e. evidence for $t$ based on $S$), and a value that is proportional to the number of missing relations from $S$ (i.e. the amount of counter-evidence). More concretely,
$$\phi(t,S)=\frac{\Sigma_{s:t\Rightarrow s\wedge s\in S}\gamma(s)}{\mu\cdot(1+\Sigma_{s:t\Rightarrow s\wedge s\not\in S}1)\cdot d(t,S)}$$
where $\mu$ is a constant and $d$ is the product of the WordNet distances of the synsets involved in $t$ to their nearest synset in $S$. This penalizes relations that are far away from categories in $S$. The optimization defined in Equation 3 is an instance of the submodular k-coverage problem. We use a greedy algorithm that adds elements in $T$ that maximize $\mathcal{L}$, which due to the submodular nature of the problem approximates the solution up to a constant factor.
이번 섹션에서, 우리는 오리지널 vocabulary $S$에서 발견되지 않은 object들에 relation $S$의 초기 set을 일반화시키는 접근을 제공한다. 우리는 $S$에 존재하는 relation을 위한 모든 가능한 부모 관계들을 포함하는 superset $G$를 WordNet을 이용하여 만드는데, 이 때, 모든 가능성있는 hypernym로 그들의 argument들인 $o_1,o_2$를 대체한다. 우리의 목표는 $G$로부터 부분집합 $T$를 선택하는 것으로, 높은 quality와 다양한 일반화된 관계를 포함해야한다. $G$의 요소는 너무 일반적일 수 있고, $S$에서는 모순된 문장일 수도 있다. 하지만 다른 것들은 정확할 수 있지만 새로운 지식은 거의 없다는 것에 유의해라. 우리는 이러한 관계에 있어 밸런스를 맞추기 위해 다음과 같은 optimization problem에서 선택을 하는데 function을 사용하였다 $\mathcal{L}$:
$\max_T \mathcal{L}(T)$, such that $|T| = k$, and $T \subseteq G$,
$\mathcal{L}(T) = \lambda\log(1+\psi(T)) + \Sigma_{t\in T}log(1+\phi(t,S))$,
$\psi$는 $T$의 원소들에 의한 하위어 관계들을 통해 암시되는 사실의 총 개수를 계산하는 coverage term이다. 두 번째 term인 $\phi$는 consistency term인데, 이는 $S$의 관계들과 함께 일반화된 relation t의 적합성을 체크한다. 우리가 만약 $S$로부터 한 관계가 누락된 경우, 그것은 거짓이라는 것을 가정한다. 이것은 ($S$의 도메인에 대해 갇혔다고 가정한다.)
그러므로, $\phi$는 $S$에 나타나는 relation이 relation $t$에 일관되는지에 대한 점수 비율이라고 할 수 있고 (예시로 $S$에 기반을 둔 $t$에 대한 증거), 그리고 $S$로부터 누락된 관계의 숫자에 비례하는 값이라고 할 수 있다 (예시로, 반증의 양).
$$\phi(t,S)=\frac{\Sigma_{s:t\Rightarrow s\wedge s\in S}\gamma(s)}{\mu\cdot(1+\Sigma_{s:t\Rightarrow s\wedge s\not\in S}1)\cdot d(t,S)}$$
이 떄, $\mu$는 상수이고, $d$는 $t$에 포함된 synset에서 $S$에 가장 가까이 존재하는 synset의 WordNet distance의 곱이다. 이것은 S에서 카테고리와 먼 relation에 패널티를 준다. Equation 3에서 정의된 optimization은 submodular k-coverage 문제의 일부분이다. 우리는 greedy algorithm을 사용하는데, 이는 $T$에 element를 추가하여 $\mathcal{L}$을 최대화시킨다. 이것은 문제의 submodular 특성에 의해 solution은 일정한 factor로서 유지된다.
*hypernym: a word whose meaning includes a group of other words.
*hyponym: 하위어
*synset: WordNet은 영어 단어를 'synset'이라는 유의어 집단으로 분류하여 간략하고 일반적인 정의를 제공하고, 이러한 어휘목록 사이의 다양한 의미 관계를 기록함.
*즉 첫 번째 텀은, generalized relations에서 부분집합을 뽑았을 때, 이 부분집합이 얼만큼의 사실들을 뒷받침하는지에 대한 적용 범위를 의미하고, 두 번째 텀은 이 일반화된 relation이 얼만큼 추출된 relation과 적합하는 지에 대한 것이다. 이 두 개의 term을 통해서 relation이 너무 일반화되지도 않게, 그리고 data로부터 추출된 사실들을 적게 포함하지도 않게 조정한다.
Experimental Setup
Object-Object Relations: We filter out from the initial set of candidate relations the ones that occur less than 20 times. We extract more than 3.1k unique statements (6k including symmetric spatial relations.)
Entailment Relations: We use skipgrams of length 2-6 allowing at most 6 skips, filter candidates such that they occur at least 5 times, and return the top 10 most likely entailments per spatial relation. Overall, 6.3k unique statements are extreacted (10k including symmetric relations).
Generalized Relations: We optimize Equation 4 only for object-object relations because the closed world assumption makes counts for implications sparse. The parameter $\mu$ is set to the average of the scores, $\lambda = 0.05$ and $k = 200$.
객체-객체 관계: 우리는 20번 보다 낮게 나타나는 것들의 후보자 관계 초기 set를 필터링 아웃한다. 우리는 3.1천개보다 많은 유니크한 상태들을 추출하였다. (6000개의 symmetric한 공간 관계를 포함하여)
귀속 관계: 우리는 최대 6 skip을 허용하여 길이 2~6짜리의 skipgram을 사용하였고, 최소 5번 나타나는 후보들을 필터링했으며, 공간 관계당 최대 10개 상위의 귀속 상태들을 반환하였다. 전체적으로 6300개의 유니크한 상태들이 추출되었다. (10000개의 symmetric 관계를 포함하여)
일반화된 관계: 우리는 Equation 4를 최적화하였는데, 오직 객체-객체 관계에만 행하였다, 왜냐하면 닫힌 공간 추측이 함축된 영향 계수를 만들기 때문이다. 파라미터들은 다음과 같이 설정되었다. $\mu$는 score의 평균 점수이며, $\lambda$는 0.05, $k$는 200으로 설정되었다.
Evaluation
We evaluated the quality of the common sense we derive on Amazon Mechanical Turk. Annotators are presented with possible facts and asked to grade statements on a five point scale. Each fact was evaluated by 10 workers and we normalize their average responses to a scale from 0 to 1. Figure 4 shows plots of quality vs. coverage, where coverage means the top percent of relations sorted by our predicted quality scores.
우리는 Amazon Mechanical Turk를 통해 상식의 질을 평가하였다. Annotator들은 가능한 사실들을 제공받고 5점 단위로 상태에 점수를 주기로 하였다. 각각의 사실들은 10명의 작업자들에 의해 평가받았고, 우리는 그들의 응답을 0에서 1사이로 normalization을 하였다. Figure 4가 해당 quality와 coverage에 대한 plot을 보여주는데, coverage는 관계의 상위 10퍼센트를 의미하고, 우리의 예측된 퀄리티 점수에 의해 정렬되었다.
Object-Object Relations
As a baseline, 1000 randomly sampled relations have a quality of 0.225. Figure 4a shows our PMI measure ranks many high quality facts at the top, with the top quintile of the ranking being rated above 0.63 in quality. Facts about persons are higher quality, likely because the category is in over 50% of the images in MS-COCO.
baseline에 의해, 1000개 무작위로 샘플된 관계들은 0.225의 퀄리티를 가지고 있다. Figure 4a가 우리의 PMI 측정이 상위 결과에 많은 높은 퀄리티의 사실을 놓고 있었고, 퀄리티로 0.63 이상 점수를 매겨진 것들은 랭킹의 상위 5분위수에 있었다. 사람들에 관한 사실들이 좀 더 높은 퀄리티를 가지고 있었고, MS-COCO의 image이 50% 이상의 카테고리이기 때문에 그런듯하였다.

Entailment Relations
Turkers were instructed to assign the lowest score when they could not understand the consequent of the entailment relation. As a baseline, 1000 randomly sampled implications that meet our patterns have a quality of 0.33. Figure 4b shows that extracting high quality entailment is harder than object-object relations likely because supposition and consequent need to coordinate. Relations involving furniture are rated higher and manual inspection revealed that many relations about furniture imply stative verbs or spatial terms.
Turk사의 사람들은 그들이 귀속 관계의 결과를 이해할 수 없을 때 가장 낮은 점수를 주도록 지시받았다. 기준선으로, 1000개의 무작위로 샘플링된 함축들을 우리의 패턴을 가질 때 0.33의 퀄리티를 가지고 있다. Figure 4b는 높은 퀄리티의 귀속 상태를 추출하는 것이 객체-객체 관계를 추출하는 것보다 어려운데, 추측과 그에 따른 조징이 필요하기 때문이다. 가구와 관련된 관계가 높은 평가를 받고, 수작업 검사에서 가구에 관한 많은 관계가 명언적 통사나 공간적 용어를 암시한다고 밝혔다.
Generalized Relations
To evaluate generalizations, Figure 4c, we also present users with *definitions. As a baseline, 200 randomly sampled generalizations from our 3k object-object relations have a quality of 0.53. Generalizations we find are high quality and cover over 400k objects facts not present in MS-COCO. Examples from the 200 we derive include: holds(dining-table, cutlery), holds(bowl, edible fruit) or on(domestic animal, bed).
*sometimes rules involve abstract concepts, for example vessel, any object that can be used as a container
일반화척도를 평가하기 위해, Figure 4c에서 우리는 유저에게 몇 가지 정의를 제공하였다. 기준선으로, 200개의 무작위로 샘플링된 3000개의 객체-객체 관계로부터의 일반화는 0.53의 퀄리티를 가지고 있다. 우리가 찾은 일반화는 높은 퀄리티를 가지고 MS-COCO에서 제공되지 않은 40만개의 객체 사실을 포함한다. 우리가 만들어낸 200개의 예시는 다음과 같다.: holds(dining-table, cutlery), holds(bowl, edible fruit) or on(domestic animal, bed).
Conclusion
이 논문에서, 우리는 annotate된 category에 대해 16000개의 상식을 추출하기 위해 객체 탐지 dataset을 사용했다. 우리는 또한 어떻게 WordNet을 일반화했는지 보여줬으며, 보이지않은 객체에 대해 몇 십만개의 사실들을 유추했다. 우리가 추출한 정보들은 시각적이고, 거대한 스케일이며 좋은 퀄리티를 가지고 있다. 그것은 매우 유용할 것이며, 시각 인지나 귀속 관계에 좋을 것이다.
--------------------------------------------------------------------------------------------------
Comments
논문을 정리해보면 다음과 같다.
먼저 시각적 상식을 뽑아내기 위해선 세 단계를 거친다.
필요한 준비물은, (1) object 범위를 표시한 mask나 polygon, (2) category V의 set으로부터 object의 category, 그리고 (3) image의 전체적인 description 이다.
1. object-object relation
객체-객체 관계를 뽑아내야한다. 이 때, 필요한 것은 image data 상에서 object 범위를 표시한 mask로 mask간 거리나 각도를 통해서 object간 연결되었는지, 위에 있는지, 옆에 있는지, disconnected되어 있는지에 대해서 판단한다.
이 때, object1과 object2에 대한 relation1을 평가하기 위해, relation1(object1, object2)가 나타나는 확률과 (object1, object2)가 나타나는 확률을 이용하여 점수를 매긴다.
2. Entailment relation
그 다음은 귀속관계를 맺는 역할이다. 이미지에 달려있는 textual description caption을 이용한다.
텍스트적 묘사로 되어있는 글들을 skip-gram을 통하여 어떠한 형태로 만들고, 그 형태내에서 나타나는 object1과 object2가 얼마나 매칭되는지 확인한 후, 매칭될 경우 entailment를 만든다. 이 때, 매칭되는 빈도, 즉 확률을 통해 entailment relation에 점수를 매긴다.
3. Generalization
그 다음은 Wordnet에 있는 hypersym과 hyposym을 이용하여 단어의 상위 하위 단계를 알아낸다음, 해당하는 superset의 부분집합이 entailment relation과 얼만큼 cover하는지, 그리고 실제로 entailment relation이 해당 일반화된 표현과 얼마나 매칭되는지에 대해 점수를 매긴다.
결과적으로, 사람에 대한 데이터가 많았기 때문에 object-object relation에서 사람 점수가 높았고, entailment와 같은 경우에는 묘사적 표현이 상상력을 가지고 하는 일이기 때문에 점수가 낮았다. furniture와 같은 경우에는 위치 표현을 항상 따르기 때문에 점수가 높았다.
이 논문에서 좋았던 점은, 시각적 사진과 텍스트 묘사를 통해 일반적인 상식을 얻어내려 했다는 점이다.
일단 기계가 상식을 얻기 위해서는 해당 데이터에만 국한되어서만 학습하는 경우가 거의 대부분이였다. 하지만 기계가 일반화된 상식을 얻기 위해 귀속 관계를 만들고 그 귀속 관계에 대해 일반화된 상식을 얻기 위해 논문과 같은 아키텍쳐를 만들었다는 점이 굉장히 신선했고 재밌었다.
하지만 역시 point-wise에 국한되었기 때문에 위치 정보에 관한 상식만 얻을 수 있었다는 점은 아쉬웠다. 전에 읽어봤던 gaze-following과 같은 정보들을 더욱 추가한다면 더 높은 성과를 나타낼 수 있다고 생각했다.
이 Section에서 우리의 목적은 relation $S_1$에 대해 점수와 랭킹을 매긴다. 이 때 $r$은 객체-객체간 관계이고, $o_1, o_2$는 Object group $V$에 포함되어 있으며, function $\gamma_1\ : S_1 \rightarrow R$를 사용한다. 먼저, 우리는 annotate된 object 쌍 사이에 object-object relation의 vocabulary $R$을 정의한다. 우리의 관계는 Figure 1에서 나타나는 디테일의 Visual Dependency Grammar와 Region Connection Calculus를 참조하였다.
For every image, we record the instances of each of these object-object relations $r(o_1,o_2)$ between all co-occurring object in $D^1$. We use Point-wise Mutual Information (PMI) to estimate the evidence for each relationship triplet:
$$\gamma_1(r(o_1,o_2)) = \log\frac{p[r(o_1,o_2)]}{p[r]p[(o_1,o_2)]}$$
모든 image 상에서, 우리는 $D^1$에 있는 모든 동시에 나타나는 object 사이에 object-object relation $r(o_1,o_2)$의 각각의 instance를 기록한다. 우리는 Point-wise Mutual Information을 사용해 각각의 관계 트리플의 증거를 추측한다:
$$\gamma_1(r(o_1,o_2)) = \log\frac{p[r(o_1,o_2)]}{p[r]p[(o_1,o_2)]}$$
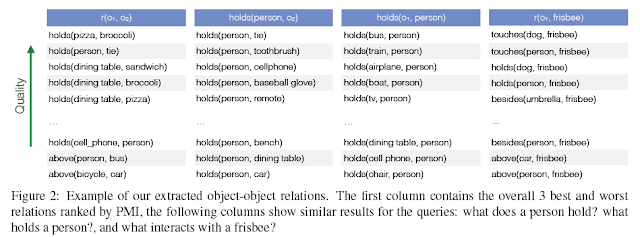
We estimate these probabilities by counting object-object-relation co-occurrences using existential quantifiers for every image. This means every image can at most contribute one to the count of $r(o_1,o_2)$ so that we do not exacerbate the results by images with many identical object types taken from unusual viewpoints. In Figure 2, we provide examples of our extracted object-object relations.
우리는 모든 image에 존재하는 객체-객체-관계의 동시 발생수를 세는 것으로 이러한 확률들을 추측한다. 이것은 모든 image가 $r(o_1,o_2)$의 갯수에 최대 한 번 기여할 수 있음을 의미하므로, 비정상적인 관점에서 많은 이상적인 객체 형태가 있는 image에 의해 결과를 악화시키지 않는다. Figure 2에서 우리는 우리가 추출한 객체-객체 관계의 예시를 제공한다.

Mining Entailment Relations
In this section we combine our relation-based tuples mined from visual annotations with more than 400k textual descriptions included in MS-COCO. We generate a set of entailments $S_2 = {r(o_1,o_2) \rightarrow z}$, where $r(o_1,o_2)$ is an element from $S_1$ and $z$ is a consequent obtained from textual descriptions. Similarly as in the previous section, we rank the relations in $S_2$ using a function $\gamma_2: S_2 \rightarrow \mathbb{R}$.
이 섹션에서는, 우리는 MS-COCO에 포함된 40만개보다 많은 텍스트 묘사와 함께 시각적 annotation으로 부터 추출된 relation-based 튜플을 결합시킨다. 우리는 귀결 규칙 $S_2 = {r(o_1,o_2) \rightarrow z}$를 set을 생성한다. 이 때, $r(o_1,o_2)$는 $S_1$으로부터의 원소이고, $z$는 텍스트 묘사로부터 얻은 결과이다. 이전 section과 유사하게, 우리는 function $\gamma_2\$를 이용하여 $S_2$의 관계들에 순위를 매긴다.
We start by generating an exhaustive list of candidate consequents $z$. We first pre-process the image-captions with the part-of-speech tagger and lemmatizer from Stanford Core NLP toolkit, and remove stop words. Then we generate a list of $n$-length skipgrams in each caption. The set of $n$-skipgrams are filtered based on predefined lexical patterns, and redundancies are removed. Skipgrams, $z$, are then paired with co-occurring relations, $r(o_1,o_2)$, removing pairs with the disconnected-from spatial relation. Pairs are scored with the conditional probability: $$\gamma_2(r(o_1,o_2) \Rightarrow z) = \frac{P[z,r(o_1,o_2)]}{P[r(o_1,o_2)]}$$
우리는 후보자 결과인 $z$의 철저한 list들을 생성하는 것으로 시작한다. 우리는 처음에 품사구문 tagger와 함께 image caption을 전처리하고, Stanford Core NLP toolkit으로부터 표제어를 찾고 stop 단어를 제거한다. 그 후 우리는 각각의 caption에서 $n$길이의 skipgram을 생성한다. $n$-skipgram set는 전에 정의된 어휘 패턴*에 기반하여 필터링 되고, 중복들이 제거된다. Skipgram, $z$는 그 후 co-occurring 관계인 $r(o_1,o_2)$와 페어링 되는데, 이 때, 공간 관계로부터 연결되지 않은 페어들은 제거된다. 페어들은 다음과 같은 조건부 확률과 함께 점수가 매겨진다:
$$\gamma_2(r(o_1,o_2) \Rightarrow z) = \frac{P[z,r(o_1,o_2)]}{P[r(o_1,o_2)]}$$
* <noun, verb>, <noun,*,verb,*,noun>, <noun,*,preposition,*,noun>, <noun,*,verb,preposition,*,noun>
The consequent $z$ can take the form $q$, $q(o_1)$, $q(o_2)$, or $q(o_1,o_2)$, by performing a simple alignment with the arguments in the antecedent. We perform this alignment by mapping the object categories in the antecedent $r(o_1,o_2)$ to WordNet synsets, and matching any word in $z$ to any word in the gloss set of the predicate arguments $o_1$ and $o_2$. The unmatched words in $z$ form the relation, whereas matched words form arguments. We produce the form $q$ if there are no matches, $q(o_1)$ ,or $q(o_2)$ when one argument word matches, and $q(o_1,o_2)$ when both match. Examples of discovered entailments are in Figure 3.
결과 $z$는 $q$, $q(o_1)$, $q(o_2)$, or $q(o_1,o_2)$와 같은 형태를 취할 수 있는데, 이는 선행사들에 있는 argument들과의 간단한 정렬을 통해 수행함으로써 시행된다. 우리는 이러한 alignment를 선행사 $r(o_1,o_2)$의 객체 카테고리를 WordNet synset에 맵핑시키는 것으로 시행하고, 그리고 $z$에 나타나는 단어를 예측 argument $o_1$와 $o_2$의 gloss set의 단어로 매칭시킨다. $z$에서 매칭되지 않은 단어들은 관계를 형성하는데, 매칭된 단어는 argument를 형성한다. 우리는 만약 match가 없을 경우에는 $q$ 형태를 생성하고. 하나의 argument word만 매칭됐을 경우에는, $q(o_1)$ 이나 $q(o_2)$를, 둘 다 매칭됐을 경우에는 $q(o_1,o_2)$를 매칭한다. 발견된 귀속 관계의 예시는 Figure 3에 있다.
* z의 형태는 <noun, verb>, <noun,*,verb,*,noun>, <noun,*,preposition,*,noun>, <noun,*,verb,preposition,*,noun>이고, 이를 co-occuring relation $r(o_1,o_2)$와 비교하여 해당 object들이 포함되어있는지 파악하고, z와 r이 같이 data set에서 존재하는가에 따라 점수를 부여한다.

Generalizing Relations using WordNet
In this section we present an approach to generalize an initial set of relations, $S$, to objects not found in the original vocabulary $V$. Using WordNet we construct a superset $G$ containing all possible parent relations for the relations in $S$ by replacing their arguments $o_1,o_2$ by all their possible hypernyms. Our objective is to select a subset $T$ from $G$ that contains high quality and diverse generalized relations. Note that elements in $G$ can be too general and contradict statements in $S$ while others could be correct but add little new knowledge. To balance these concerns, we formulate the selection as an optimization problem by maximizing a fitness function $\mathcal{L}$:
$\max_T \mathcal{L}(T)$, such that $|T| = k$, and $T \subseteq G$,
$\mathcal{L}(T) = \lambda\log(1+\psi(T)) + \Sigma_{t\in T}log(1+\phi(t,S))$,
where $\psi$ is a coverage term that computes the total number of facts implied through hyponym relationships by the elements in $T$. The second term $\phi$ is a consistency term measures the compatibility of a generalized relation t with the relations in $S$. We assume that if a relation is missing from $S$, then it is false (this corresponds to a closed world assumption over the domain of $S$). Thus, $\phi$ is the ratio of the scores of relations in $S$ consistent with relation $t$ (i.e. evidence for $t$ based on $S$), and a value that is proportional to the number of missing relations from $S$ (i.e. the amount of counter-evidence). More concretely,
$$\phi(t,S)=\frac{\Sigma_{s:t\Rightarrow s\wedge s\in S}\gamma(s)}{\mu\cdot(1+\Sigma_{s:t\Rightarrow s\wedge s\not\in S}1)\cdot d(t,S)}$$
where $\mu$ is a constant and $d$ is the product of the WordNet distances of the synsets involved in $t$ to their nearest synset in $S$. This penalizes relations that are far away from categories in $S$. The optimization defined in Equation 3 is an instance of the submodular k-coverage problem. We use a greedy algorithm that adds elements in $T$ that maximize $\mathcal{L}$, which due to the submodular nature of the problem approximates the solution up to a constant factor.
이번 섹션에서, 우리는 오리지널 vocabulary $S$에서 발견되지 않은 object들에 relation $S$의 초기 set을 일반화시키는 접근을 제공한다. 우리는 $S$에 존재하는 relation을 위한 모든 가능한 부모 관계들을 포함하는 superset $G$를 WordNet을 이용하여 만드는데, 이 때, 모든 가능성있는 hypernym로 그들의 argument들인 $o_1,o_2$를 대체한다. 우리의 목표는 $G$로부터 부분집합 $T$를 선택하는 것으로, 높은 quality와 다양한 일반화된 관계를 포함해야한다. $G$의 요소는 너무 일반적일 수 있고, $S$에서는 모순된 문장일 수도 있다. 하지만 다른 것들은 정확할 수 있지만 새로운 지식은 거의 없다는 것에 유의해라. 우리는 이러한 관계에 있어 밸런스를 맞추기 위해 다음과 같은 optimization problem에서 선택을 하는데 function을 사용하였다 $\mathcal{L}$:
$\max_T \mathcal{L}(T)$, such that $|T| = k$, and $T \subseteq G$,
$\mathcal{L}(T) = \lambda\log(1+\psi(T)) + \Sigma_{t\in T}log(1+\phi(t,S))$,
$\psi$는 $T$의 원소들에 의한 하위어 관계들을 통해 암시되는 사실의 총 개수를 계산하는 coverage term이다. 두 번째 term인 $\phi$는 consistency term인데, 이는 $S$의 관계들과 함께 일반화된 relation t의 적합성을 체크한다. 우리가 만약 $S$로부터 한 관계가 누락된 경우, 그것은 거짓이라는 것을 가정한다. 이것은 ($S$의 도메인에 대해 갇혔다고 가정한다.)
그러므로, $\phi$는 $S$에 나타나는 relation이 relation $t$에 일관되는지에 대한 점수 비율이라고 할 수 있고 (예시로 $S$에 기반을 둔 $t$에 대한 증거), 그리고 $S$로부터 누락된 관계의 숫자에 비례하는 값이라고 할 수 있다 (예시로, 반증의 양).
$$\phi(t,S)=\frac{\Sigma_{s:t\Rightarrow s\wedge s\in S}\gamma(s)}{\mu\cdot(1+\Sigma_{s:t\Rightarrow s\wedge s\not\in S}1)\cdot d(t,S)}$$
이 떄, $\mu$는 상수이고, $d$는 $t$에 포함된 synset에서 $S$에 가장 가까이 존재하는 synset의 WordNet distance의 곱이다. 이것은 S에서 카테고리와 먼 relation에 패널티를 준다. Equation 3에서 정의된 optimization은 submodular k-coverage 문제의 일부분이다. 우리는 greedy algorithm을 사용하는데, 이는 $T$에 element를 추가하여 $\mathcal{L}$을 최대화시킨다. 이것은 문제의 submodular 특성에 의해 solution은 일정한 factor로서 유지된다.
*hypernym: a word whose meaning includes a group of other words.
*hyponym: 하위어
*synset: WordNet은 영어 단어를 'synset'이라는 유의어 집단으로 분류하여 간략하고 일반적인 정의를 제공하고, 이러한 어휘목록 사이의 다양한 의미 관계를 기록함.
*즉 첫 번째 텀은, generalized relations에서 부분집합을 뽑았을 때, 이 부분집합이 얼만큼의 사실들을 뒷받침하는지에 대한 적용 범위를 의미하고, 두 번째 텀은 이 일반화된 relation이 얼만큼 추출된 relation과 적합하는 지에 대한 것이다. 이 두 개의 term을 통해서 relation이 너무 일반화되지도 않게, 그리고 data로부터 추출된 사실들을 적게 포함하지도 않게 조정한다.
Experimental Setup
Object-Object Relations: We filter out from the initial set of candidate relations the ones that occur less than 20 times. We extract more than 3.1k unique statements (6k including symmetric spatial relations.)
Entailment Relations: We use skipgrams of length 2-6 allowing at most 6 skips, filter candidates such that they occur at least 5 times, and return the top 10 most likely entailments per spatial relation. Overall, 6.3k unique statements are extreacted (10k including symmetric relations).
Generalized Relations: We optimize Equation 4 only for object-object relations because the closed world assumption makes counts for implications sparse. The parameter $\mu$ is set to the average of the scores, $\lambda = 0.05$ and $k = 200$.
객체-객체 관계: 우리는 20번 보다 낮게 나타나는 것들의 후보자 관계 초기 set를 필터링 아웃한다. 우리는 3.1천개보다 많은 유니크한 상태들을 추출하였다. (6000개의 symmetric한 공간 관계를 포함하여)
귀속 관계: 우리는 최대 6 skip을 허용하여 길이 2~6짜리의 skipgram을 사용하였고, 최소 5번 나타나는 후보들을 필터링했으며, 공간 관계당 최대 10개 상위의 귀속 상태들을 반환하였다. 전체적으로 6300개의 유니크한 상태들이 추출되었다. (10000개의 symmetric 관계를 포함하여)
일반화된 관계: 우리는 Equation 4를 최적화하였는데, 오직 객체-객체 관계에만 행하였다, 왜냐하면 닫힌 공간 추측이 함축된 영향 계수를 만들기 때문이다. 파라미터들은 다음과 같이 설정되었다. $\mu$는 score의 평균 점수이며, $\lambda$는 0.05, $k$는 200으로 설정되었다.
Evaluation
We evaluated the quality of the common sense we derive on Amazon Mechanical Turk. Annotators are presented with possible facts and asked to grade statements on a five point scale. Each fact was evaluated by 10 workers and we normalize their average responses to a scale from 0 to 1. Figure 4 shows plots of quality vs. coverage, where coverage means the top percent of relations sorted by our predicted quality scores.
우리는 Amazon Mechanical Turk를 통해 상식의 질을 평가하였다. Annotator들은 가능한 사실들을 제공받고 5점 단위로 상태에 점수를 주기로 하였다. 각각의 사실들은 10명의 작업자들에 의해 평가받았고, 우리는 그들의 응답을 0에서 1사이로 normalization을 하였다. Figure 4가 해당 quality와 coverage에 대한 plot을 보여주는데, coverage는 관계의 상위 10퍼센트를 의미하고, 우리의 예측된 퀄리티 점수에 의해 정렬되었다.
Object-Object Relations
As a baseline, 1000 randomly sampled relations have a quality of 0.225. Figure 4a shows our PMI measure ranks many high quality facts at the top, with the top quintile of the ranking being rated above 0.63 in quality. Facts about persons are higher quality, likely because the category is in over 50% of the images in MS-COCO.
baseline에 의해, 1000개 무작위로 샘플된 관계들은 0.225의 퀄리티를 가지고 있다. Figure 4a가 우리의 PMI 측정이 상위 결과에 많은 높은 퀄리티의 사실을 놓고 있었고, 퀄리티로 0.63 이상 점수를 매겨진 것들은 랭킹의 상위 5분위수에 있었다. 사람들에 관한 사실들이 좀 더 높은 퀄리티를 가지고 있었고, MS-COCO의 image이 50% 이상의 카테고리이기 때문에 그런듯하였다.
Entailment Relations
Turkers were instructed to assign the lowest score when they could not understand the consequent of the entailment relation. As a baseline, 1000 randomly sampled implications that meet our patterns have a quality of 0.33. Figure 4b shows that extracting high quality entailment is harder than object-object relations likely because supposition and consequent need to coordinate. Relations involving furniture are rated higher and manual inspection revealed that many relations about furniture imply stative verbs or spatial terms.
Turk사의 사람들은 그들이 귀속 관계의 결과를 이해할 수 없을 때 가장 낮은 점수를 주도록 지시받았다. 기준선으로, 1000개의 무작위로 샘플링된 함축들을 우리의 패턴을 가질 때 0.33의 퀄리티를 가지고 있다. Figure 4b는 높은 퀄리티의 귀속 상태를 추출하는 것이 객체-객체 관계를 추출하는 것보다 어려운데, 추측과 그에 따른 조징이 필요하기 때문이다. 가구와 관련된 관계가 높은 평가를 받고, 수작업 검사에서 가구에 관한 많은 관계가 명언적 통사나 공간적 용어를 암시한다고 밝혔다.
Generalized Relations
To evaluate generalizations, Figure 4c, we also present users with *definitions. As a baseline, 200 randomly sampled generalizations from our 3k object-object relations have a quality of 0.53. Generalizations we find are high quality and cover over 400k objects facts not present in MS-COCO. Examples from the 200 we derive include: holds(dining-table, cutlery), holds(bowl, edible fruit) or on(domestic animal, bed).
*sometimes rules involve abstract concepts, for example vessel, any object that can be used as a container
일반화척도를 평가하기 위해, Figure 4c에서 우리는 유저에게 몇 가지 정의를 제공하였다. 기준선으로, 200개의 무작위로 샘플링된 3000개의 객체-객체 관계로부터의 일반화는 0.53의 퀄리티를 가지고 있다. 우리가 찾은 일반화는 높은 퀄리티를 가지고 MS-COCO에서 제공되지 않은 40만개의 객체 사실을 포함한다. 우리가 만들어낸 200개의 예시는 다음과 같다.: holds(dining-table, cutlery), holds(bowl, edible fruit) or on(domestic animal, bed).
Conclusion
이 논문에서, 우리는 annotate된 category에 대해 16000개의 상식을 추출하기 위해 객체 탐지 dataset을 사용했다. 우리는 또한 어떻게 WordNet을 일반화했는지 보여줬으며, 보이지않은 객체에 대해 몇 십만개의 사실들을 유추했다. 우리가 추출한 정보들은 시각적이고, 거대한 스케일이며 좋은 퀄리티를 가지고 있다. 그것은 매우 유용할 것이며, 시각 인지나 귀속 관계에 좋을 것이다.
--------------------------------------------------------------------------------------------------
Comments
논문을 정리해보면 다음과 같다.
먼저 시각적 상식을 뽑아내기 위해선 세 단계를 거친다.
필요한 준비물은, (1) object 범위를 표시한 mask나 polygon, (2) category V의 set으로부터 object의 category, 그리고 (3) image의 전체적인 description 이다.
1. object-object relation
객체-객체 관계를 뽑아내야한다. 이 때, 필요한 것은 image data 상에서 object 범위를 표시한 mask로 mask간 거리나 각도를 통해서 object간 연결되었는지, 위에 있는지, 옆에 있는지, disconnected되어 있는지에 대해서 판단한다.
이 때, object1과 object2에 대한 relation1을 평가하기 위해, relation1(object1, object2)가 나타나는 확률과 (object1, object2)가 나타나는 확률을 이용하여 점수를 매긴다.
2. Entailment relation
그 다음은 귀속관계를 맺는 역할이다. 이미지에 달려있는 textual description caption을 이용한다.
텍스트적 묘사로 되어있는 글들을 skip-gram을 통하여 어떠한 형태로 만들고, 그 형태내에서 나타나는 object1과 object2가 얼마나 매칭되는지 확인한 후, 매칭될 경우 entailment를 만든다. 이 때, 매칭되는 빈도, 즉 확률을 통해 entailment relation에 점수를 매긴다.
3. Generalization
그 다음은 Wordnet에 있는 hypersym과 hyposym을 이용하여 단어의 상위 하위 단계를 알아낸다음, 해당하는 superset의 부분집합이 entailment relation과 얼만큼 cover하는지, 그리고 실제로 entailment relation이 해당 일반화된 표현과 얼마나 매칭되는지에 대해 점수를 매긴다.
결과적으로, 사람에 대한 데이터가 많았기 때문에 object-object relation에서 사람 점수가 높았고, entailment와 같은 경우에는 묘사적 표현이 상상력을 가지고 하는 일이기 때문에 점수가 낮았다. furniture와 같은 경우에는 위치 표현을 항상 따르기 때문에 점수가 높았다.
이 논문에서 좋았던 점은, 시각적 사진과 텍스트 묘사를 통해 일반적인 상식을 얻어내려 했다는 점이다.
일단 기계가 상식을 얻기 위해서는 해당 데이터에만 국한되어서만 학습하는 경우가 거의 대부분이였다. 하지만 기계가 일반화된 상식을 얻기 위해 귀속 관계를 만들고 그 귀속 관계에 대해 일반화된 상식을 얻기 위해 논문과 같은 아키텍쳐를 만들었다는 점이 굉장히 신선했고 재밌었다.
하지만 역시 point-wise에 국한되었기 때문에 위치 정보에 관한 상식만 얻을 수 있었다는 점은 아쉬웠다. 전에 읽어봤던 gaze-following과 같은 정보들을 더욱 추가한다면 더 높은 성과를 나타낼 수 있다고 생각했다.

댓글
댓글 쓰기